Feed: Astral Codex Ten
I hate the term “hallucinations” for when AIs say false things. It’s perfectly calculated to mislead the reader - to make them think AIs are crazy, or maybe just have incomprehensible failure modes.
AIs say false things for the same reason you do.
At least, I did. In school, I would take multiple choice tests. When I didn’t know the answer to a question, I would guess. Schoolchild urban legend said that “C” was the best bet, so I would fill in bubble C. It was fine. Probably got a couple extra points that way, maybe raised my GPA by 0.1 over the counterfactual.
Some kids never guessed. They thought it was dishonest. I had trouble understanding them, but when I think back on it, I had limits too. I would guess on multiple choice questions, but never the short answer section. “Who invented the cotton gin?” For any “who invented” question in US History, there’s a 10% chance it’s Thomas Edison. Still, I never put down his name. “Who negotiated the purchase of southern Arizona from Mexico?” The most common name in the United States has long been “John Smith”, applying to 1/10,000 individuals. An 0.01% chance of getting a question right is better than zero, right? If I’d guessed “John Smith” for every short answer question I didn’t know, I might have gotten ~1 extra point in my school career, with no downside.
You can go further. Consider an essay question: “Describe the invention of the cotton gin and its effect on American history, citing your sources.” Suppose I slept when I should have studied and knew nothing about this. A one-in-a-million chance of getting it correct is better than literally zero, right?
The cotton gin was invented by Thomas Edison in 1910. It was important because gin made with cotton, of which the Southern plantation economy produced a surplus, was cheaper than the usual gin made with juniper berries. This lowered the price of alcoholic spirits considerably. According to historian John Smith in his seminal The Invention Of The Cotton Gin For Dummies, the resulting boom in alcoholism provoked a backlash that ultimately led to Prohibition.
I won’t say no human has ever done this, because I remember one kid doing it during a presentation in twelfth grade. It was so embarrassing (for him) that it remains seared in my memory - which sufficiently explains why most of us don’t try it. A one-in-a-million chance of a better grade isn’t worth the shame of a 999,999-in-a-million chance of sounding like an idiot.
AIs have no shame. Their entire training process is based on guessing (the polite term is “prediction”). It goes like this:
AIs start with random weights, ie total chaos.
They’re asked to predict the next token in a text.
They give a random answer.
When they get it wrong, the training process slightly updates their weights towards the pattern that would have gotten it right.
After billions of tokens, their weights are in a good, nonrandom pattern that often predicts the next token successfully.
But even after step 5, they’re still guessing. Consider the following sentence: “I went out with my friend Mr. _______ “. With your human knowledge, you can predict that the token in the blank will be a surname. But you have no way to know which. If your life was on the line, you might guess “Smith”, since it’s the most common surname. Even the smartest AI can do little better.
And over the massive training process, even the craziest guesses sometimes pay off. Imagine you took one hundred trillion history classes. One in every million times you wrote a fake essay like the one above, your teacher said “Great job, that was exactly right, here’s a gold star.”
So the interesting question isn’t why AIs hallucinate: during training, guessing correctly is rewarded, guessing incorrectly isn’t punished, so the rational strategy is to always guess (and increase your chance of being right from 0 to 0.001%). Since AIs in normal consumer use follow the strategies they learned during training, they guess there too. The interesting question is why AIs sometimes don’t hallucinate. Here the answer is that the AI starts out hallucinating 100% of the time, the AI companies do things during post-training to bring that number down, and eventually they reduce it to “acceptable” levels and release it to users.
How do we know this is what’s happening? When researchers observe an AI mid-hallucination, they see the model activates features related to deception - ie fails an AI lie detector test. The original title of this post was “Lies, Not Hallucinations” and I still like this framing - the AI knows what it’s doing, in the same way you’d know you were trying to pull one over on your teacher by writing a fake essay. But friends talked me out of the lie framing. The AI doesn’t have a better answer than “John Smith”. It’s giving its real best guess - while knowing that the chance it’s right is very small.
Why does this matter? I often see people in the stochastic parrot faction say that AIs can’t be doing anything like humans, because they have this bizarre inhuman failure mode, “hallucinations” which is incompatible with being a normal mind that has some idea what’s going on. Therefore, it must be some kind of blind pattern-matching algorithm. Calling them “shameless guesses” hammers in that the AI is doing something so human and natural that you probably did it yourself during your student days.
Understood correctly, this is a story about alignment. AIs are smart enough to understand the game they’re actually playing - the game of determining strategies that get reward during pretraining. We just haven’t figured out how to align their reward function (get a high score on the pretraining algorithm) with our own desires (provide useful advice). People will say with a straight face “I don’t worry about alignment because I’ve never seen any alignment failures . . . and also, all those crazy hallucinations prove AIs are too dumb to be dangerous.”
This is the weekly visible open thread. Post about anything you want, ask random questions, whatever. ACX has an unofficial subreddit, Discord, and bulletin board, and in-person meetups around the world. Most content is free, some is subscriber only; you can subscribe here. Also:
1: Another ACX Forecasting Contest winner has come forth and revealed themselves. Giacomo P is a statistics PhD working on Bayesian methods. He's looking for an academic job; if you are hiring, read more about him here. He also asks that any "law nerd" who reads this bet on his prediction markets about an upcoming Italian referendum , which will help him cast an informed vote next Sunday.
2: Some good responses to the post on the constitutional amendment about Giant Congress. In case you were wondering whether the reversed meaning in the amendment was really a typo, commenter i_eat_pork tracked down the history, and yeah, definitely a typo. And commenter Caral found that the amendment might have been passed by an extra state in 1790, and therefore should be considered ratified - but DC was never informed, and there’s no clear way to tell the legal system “hey, there’s a amendment you don’t know about which should legally be in effect”. A job for an enterprising constitutional lawyer?
3: Some ACX readers wish me to advertise that they’ve started Nectome, a revolutionary new cryonics company (ie preserve your dead body intact in case the future learns how to revive people). They write:
We preserve the whole body, including the brain, at nanoscale, subsynaptic detail. We are capable of preserving every neuron and every synapse in the brain, and almost every protein, lipid, and nucleic acid within each cell and throughout the entire body is held in place by molecular crosslinks…unlike previous cryonics methods that required extremely low-temperature liquid nitrogen coolant, our method is stable for months at room temperature and compatible with traditional funeral practices.
More information here, and they have a pre-sale (at $100,000 per body) going on until the end of April.
4: New subscribers-only post, Lines Composed In A Fake Sequoia Forest. If you see a beautiful photo, and later learn it was AI-generated, are you harmed? What is the harm?
There are ACX meetup groups all over the world. Lots of people are vaguely interested, but don’t try them out until I make a big deal about it on the blog. Some people who try meetups out realize they love ACX meetups and start going regularly. Since learning that, I’ve tried to make a big deal about it on the blog twice annually, and it’s that time of year again.
If you’re willing to organize a meetup for your city please fill out the organizer form by March 26th.
The form will ask you to pick a location, time, and date, and to provide an email address where people can reach you for questions. It will also ask a few short questions about how excited you are to run the meetup to help pick between multiple organizers in the same city. One meetup per city will be advertised on the blog, and people can get in touch with you about details or just show up.
Organizing an ACX Everywhere meetup can be easy. Pick a time and a place (parks work well if you think there will be a lot of people, cafes or apartments work fine for fewer) and show up with a sign saying “ACX Meetup.” You don’t need to have discussion plans or a group activity. If you want to make the experience better for people, you can bring nice things like nametags, food and drinks, or games. Meetups Czar Skyler can reimburse you for the nametags, food, drinks, and other things like that, though reimbursements are likely going to go out slower than last year.
Here’s a short FAQ for potential meetup organizers:
1. How do I know if I would be a good meetup organizer?
If you can put a name/time/date in a box on Google Forms and show up there, you have the minimum skill necessary to be a meetup organizer for your city, and I recommend you volunteer.
Don’t worry, you volunteering won’t take the job away from someone more deserving. The form will ask people how excited/qualified they are about being an organizer, and if there are many options, I’ll choose between them. (Or Meetups Czar Skyler will.) But a lot of cities might not have an excited/qualified person, in which case I would rather the unexcited/unqualified people sign up, than have nobody available at all. If you are the leader of your city’s existing meetup group, please fill in the form anyway and say so. That lets me know you’re still active, and also importantly lets me know when your meetup is planned for.
This spreadsheet shows the cities where someone has filled out the form, updated manually after checking it makes sense. If you don’t see your city listed, either nobody has yet signed up or they did it recently after the last check. Beware the Bystander Effect!
2. How will people hear about the meetup?
You give me the information, and on March 27th (or so), I’ll post it on ACX. An event will also be created on LessWrong’s Community page.
3. When should I plan the meetup for?
Since I’ll post the list of meetup times and dates around March 27th, please choose sometime after that. Any day April 1st through May 31st is okay. Weekends are usually good, since it’s when most people are available. You’ll probably get more attendance if you schedule for at least one week out, but not so far out that people will forget - so mid April or early May would be best. If you’re in a college town, it might be worth checking the local graduation dates and avoiding those.
4. How many people should I expect?
Historically these meetups get anywhere from zero to over a hundred. Meetups in big US cities (especially ones with universities or tech hubs) had the most people; meetups in non-English-speaking countries had the fewest. You can see a list of every city and how many attendees most of them had last time here. Plan accordingly. If it looks like your city probably won’t have many attendees, maybe bring a friend or a book so you’ll have a good time even if nobody shows up.
5. Where should I hold the meetup?
A good venue should be easy for people to get to, not too loud, and have basic things like places to sit, access to toilets, and the option of acquiring food and water. City parks and mall common areas work well. If you want to hold the meetup at your house, remember that this will involve me posting your address on the Internet. If you want to hold the meetup at a pub or bar, remember that college students or parents with children who want to attend might not be able to get in.
6. What should I do at the meetup?
Mostly people just show up and talk. If you’re worried about this not going well, here are some things that can help:
Have people indicate topics they’re interested in by writing something on their nametag.
Write some icebreakers / conversation starters on index cards (e.g. “What have you been excited about recently?” or “How did you find the blog?” or “How many feet of giraffe neck do you think there are in the world?”) and leave them lying around to start discussions.
Say hello to people as they arrive and introduce yourself.
In general I would warn against trying to impose mandatory activities (e.g. “now we’re all going to sit down and watch a PowerPoint presentation”), but it’s fine to give people the option to do something other than freeform socializing (e.g. “go over to that table if you want to play a game”).
7. Is it okay if I already have an existing meetup group?
Yes. If you run an existing ACX meetup group, just choose one of your meetings which you’d like me to advertise on my blog as the official meetup for your city, and be prepared to have a larger-than-normal attendance who might want to do generic-new-people things that day.
If you’re a LW, EA, or other affiliated community meetup group, consider carefully whether you want to be affiliated with ACX. If you decide yes, that’s fine, but I might still choose an ACX-specific meetup over you, if I find one. I guess this would depend on whether you’re primarily a social group (good for this purpose) vs. a practical group that does rationality/altruism/etc activism (good for you, but not really appropriate for what I’m trying to do here). I’ll ask about this on the form.
8. If this works, am I committing to continuing to organize meetup groups forever for my city?
The short answer is no.
The long answer is no, but it seems like the sort of thing somebody should do. Many cities already have permanent meetup groups. For the others, I’ll prioritize would-be organizers who are interested in starting one. If you end up organizing one meetup but not being interested in starting a longer-term group, see if you can find someone at the meetup who you can hand this responsibility off to.
I know it sounds weird, but due to the way human psychology works, once you’re the meetup organizer people are going to respect you, coordinate around you, and be wary of doing anything on their own initiative lest they step on your toes. If you can just bang something loudly at the meetup, get everyone’s attention, and say “HEY, ANYONE WANT TO BECOME A REGULAR MEETUP ORGANIZER?”, somebody might say yes, even if they would never dream of asking you on their own and wouldn’t have decided to run things without someone offering.
If someone does want to run things regularly, you or they can offer to collect people’s names and emails if they’re interested in future meetups. You could do this with a pen and paper, or if you’re concerned about reading people’s handwriting, you could use a QR code/bitly link to a Google Form.
9. Are you (Scott) going to come to some of the meetups?
I have in the past, but this year I’ll probably only be able to make my local one in Berkeley.
10. What if I have other questions?
Skyler and I will read the comments here.
Again, you can find the meetup organizer volunteer form here. If you want to know if anyone has signed up to run a meetup for your city, you can view that here. Everyone else, just wait until around 3/27 and I’ll give you more information on where to go then.
[This is a guest post, written by David Speiser, author of the Ollantay review in last year’s Non-Book Review contest. David provided the concept and original draft; Scott edited the final version. Remaining mistakes are likely mine (Scott’s)]
The Problem
Everyone hates Congress. That poll showing that cockroaches are more popular than Congress is now thirteen years old, and things haven’t improved in those thirteen years. Congressional approval dipped below 20% during the Great Recession and hasn’t recovered since.
A republic where a supermajority of citizens neither like nor trust their representatives is not the most stable of foundations, so it should not be shocking that the legislative branch is being subsumed by the executive.
What’s the solution? Many have been proposed, some with very snazzy websites. FairVote thinks that ranked choice voting and proportional representation will solve it. The Congressional Reform Project has another snazzy website with such bold proposals as “Increase the opportunity for Members to form relationships across party lines, including by bipartisan issues conferences.” There are more think tanks. They want to enlarge the House by a few hundred members, switch to a biennial budget system, spend more on Congressional staffers, and introduce term limits, among many other suggestions.
There are op-eds too. Here’s how the Atlantic wants to fix Congress. The New York Times of course has a solution. Here on Substack, Matt Yglesias thinks proportional representation is the solution, and Nicholas Decker has an especially interesting solution.
These proposals, no matter which direction they’re coming from, have two things in common. The first is that they largely agree on the problem: members of Congress are disconnected from their constituents. Thanks to a combination of huge gerrymandered districts, national partisan polarization, and the influence of large donors, a representative has little incentive to care about the experience of individual people in their district.
The second thing that all these proposed solutions have in common is that none of them will ever be implemented. They all involve acts of Congress - and members of Congress have no incentive to vote to change broken systems that currently benefit them. Why would you want to stop gerrymandering when it’s the reason you don’t have to run a real campaign to stay in office? Why would you vote to give yourself more work? Why would you vote to make it harder for people to give you money? If we want to fix Congress, we need a solution that doesn’t involve Congress.
Luckily for us, such a solution exists: if we get 27 states to ratify the Congressional Apportionment Amendment, then we can make some real progress towards fixing Congress without Congressional buy-in. This solution is not a new idea. It comes up every few years and gets little traction. My hope in writing this piece is that it gets more traction now.
The Only A+ Ever Given At The University Of Texas
In 1789, Congress passed the Bill of Rights, containing twelve Constitutional amendments meant to protect the American people. Ten of these twelve were ratified by the states and became law. Two failed and were forgotten.
Eighty three years later - in 1872 - a Congress voted themselves a pay raise1. In fact, they voted themselves a pay raise effective as of two years ago, meaning that every member of Congress immediately received two years of back pay.
The American people were outraged, especially after an economic crisis hit later that year. In the midst of the backlash, a member of the Ohio state legislature remembered the failed eleventh amendment in the Bill of Rights, which read:
No law, varying the compensation for the services of the Senators and Representatives, shall take effect, until an election of Representatives shall have intervened.
In other words, if Congress votes themselves a pay raise, it can’t take effect before the next election cycle. Ohio decided - better late than never - and became the 9th state to ratify the amendment, almost a century after the first eight. But it still wasn’t enough, and besides, the American people punished Congress in a more traditional way: they voted the Republican majority out of office and handed the chamber to the Democrats. Everyone forgot the eleventh amendment a second time.
One hundred ten years later - in 1982 - an undergrad at University of Texas in Austin wrote a paper on the pay-raise amendment, mentioning that there wasn’t technically anything in the Constitution that said that amendments had expiration dates. He got a C on the paper and very reasonably turned that into a decade-long crusade to prove his history teacher wrong. He started a nationwide campaign to get state legislatures to ratify the amendment. In 1992, he succeeded: the 38th state approved the provision, and it was added to the Constitution as what is now the Twenty-Seventh Amendment. The crusade worked; thirty-four years after the original paper, his political science teacher submitted a petition to the university to retroactively change his grade to an A+; since there is no A+ on the official UT grading rubric, this became the only A+ ever given in the history of the University of Texas.
That means eleven of the original twelve Bill of Rights amendments have made it into the Constitution. There’s only one left. It’s been ratified by eleven states already. If twenty-seven more states agree, it will become the law of the land. It is the right to Giant Congress.
The Right To Giant Congress
Here is the text of the Congressional Apportionment Amendment, the sole unratified amendment from the Bill of Rights:
After the first enumeration required by the first article of the Constitution, there shall be one Representative for every thirty thousand, until the number shall amount to one hundred, after which the proportion shall be so regulated by Congress, that there shall be not less than one hundred Representatives, nor less than one Representative for every forty thousand persons, until the number of Representatives shall amount to two hundred, after which the proportion shall be so regulated by Congress, that there shall not be less than two hundred Representatives, nor more than one Representative for every fifty thousand persons.
In other words, there will be one Representative per X people, depending on the size of the US. Once the US is big enough, it will top out at one Representative per 50,000 citizens.
(if you’ve noticed something off about this description, good work - we’ll cover it in the section “A Troublesome Typo”, near the end)
The US is far bigger than in the Framers’ time, so it’s the 50,000 number that would apply in the present day. This would increase the size of the House of Representatives from 435 reps to 6,6412. Wyoming would have 12 seats; California would have 791. Here’s a map:
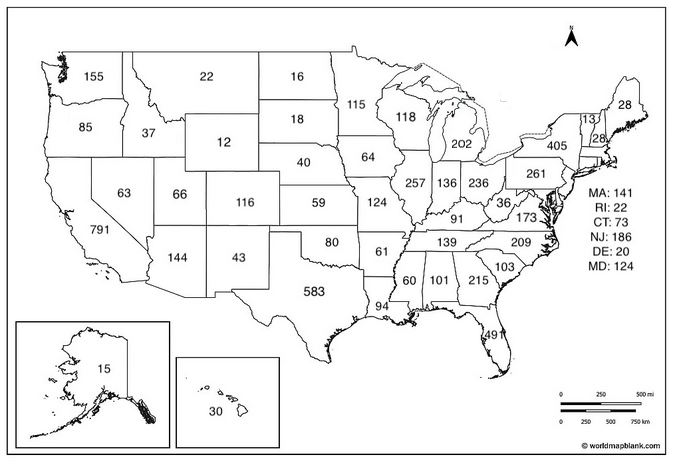
This would give the U.S. the largest legislature in the world, topping the 2,904-member National People’s Congress of China. It would land us right about the middle of the list of citizens per representative, at #104, right between Hungary and Qatar (we currently sit at #3, right between Afghanistan and Pakistan).
Would this solve the issues that make Congress so hated? It would be a step in the right direction. Our various think tanks identified three primary reasons behind the estrangement of Congress and citizens: gerrymandering, national partisan polarization, and the influence of large donors. This fixes, or at least ameliorates, all of them.
Gerrymandering: Gerrymandering many small districts is a harder problem than gerrymandering a few big ones. Durable gerrymandering requires drawing districts with the exact right combination of cities and rural areas, but there are only a limited number of each per state. With too many districts, achievable margins decrease and the gerrymander is more likely to fail.
We can see this with state legislatures vs. congressional delegations. A dominant party has equal incentive to gerrymander each, but most states have more legislature seats than Congressional ones, and so the legislatures end up less gerrymandered. Here are some real numbers from last election cycle3:

So for example, in Republican-dominated North Carolina, 50.9% of people voted Trump, 60% of state senate seats are held by Republicans, and 71.4% of their House seats belong to Republicans. The state senate (50 seats) is only half as gerrymandered as the House delegation (14 seats).
In many states, the new CAA-compliant delegation would be about the same size as the state legislature, and so could also be expected to halve gerrymandering.
As a bonus, the Electoral College bias towards small states would be essentially solved. Currently, a Wyomingite’s presidential vote controls three times as many electoral votes as a Californian’s. Under the CAA, both states would be about equal.
Money: This one is intuitive. If you can effectively buy 1/435 elections, you’ve bought 0.23% of Congress. If the same money only buys you 0.02% of Congress, you’re less incentivized to try to buy House elections and more incentivized to try to buy Senate seats or just to gain influence within a given political party. Money in politics is still a thing, but it becomes much harder to coordinate among people. This makes it easier for somebody to run for Congress without having to fundraise millions of dollars. Because it’s less worth it to spend so much money on any one seat, elections to the House become cheaper4.
Polarization: Some of the think tanks that want to increase the size of Congress by a few hundred members rather than a few thousand claim that this increase will fix political polarization by making representatives more answerable to their constituents who tend to care more about local issues than national ones.
I’m more skeptical of this claim, mainly because it seems that all politics is national politics now. There’s one newspaper and three websites and all they care about is national politics. My Congressional representative ran for office touting her background in energy conservation and water management, arguing that in a drying state and a warming climate we really need somebody in Congress who knows water problems inside and out. Now that she’s actually in Congress, it seems that her main job is calling Donald Trump a pedophile5. The incentives here are to get noticed by the press and to go viral talking about how evil the other side is, so that people who are angry at the evil other side will give you money and you can win your next election.
But maybe Big Congress can solve that. Maybe in a district of less than 50,000 there will be less incentive to go viral and more incentive to connect with your constituents. At the very least, it seems that people trust their state representatives more. And when my state representative and my state Senator tell me about the good work that they’ve done and ask for me to vote for them again, they point to legislation that they’ve passed, not clips of them calling their opponents pedophiles.
Won’t Congress Become Unmanageable?
At first, probably yes!
The Capitol Building couldn’t fit a 6,641 person Congress, let alone all of the extra staffers and administrative personnel who would come with it. We’d need to build a new monument to the largest democratic body in the history of the world. This is a good thing.
But it would also become conceptually unmanageable, with individual members having more trouble networking with one another and sounding out consensus. I expect that out of necessity, the House would take on a more parliamentary form with the party as the baseline for decision making. Then the big negotiations become those between parties, not between individuals.
Why Should I Support This?
Democrats: You’re about to take a beating in the next census. California is moving to gerrymander its Congressional delegation, but it’s also going to lose four seats. Texas is moving to gerrymander its delegation even more aggressively, and it’s going to gain four seats. Florida is going to gain three. Illinois and New York are losing seats. Across the board it’s bad news; while you might come out on top in this year’s elections, you’re going to lose the gerrymandering battle come 2030. Ratifying the CAA will make the battle that much fairer for you.
Republicans: You’re about to take a beating in the midterms. The aggressive gerrymandering in Texas could easily backfire in a blue year, and California just passed the “I Hate Republicans” act to gerrymander that state as well. Ratifying the CAA is a way to blunt the effect, and let your colleagues in Illinois and California and New England have their voices heard. But there’s a bigger reason for you to want to support this. If you’re a Republican in 2026, you exist to serve Donald Trump and his vision for America. You want to help Donald Trump recreate America in his image. The image of America will be the image of the new Capitol Building, and Donald Trump will lead this design. You saw how excited he was about the east wing of the White House; imagine how ecstatic he would be to get to design the Donald J. Trump Capitol Building. Imagine how owned all those Washington libs will be when they walk by the giant golden statue of Donald Trump that hosts Congress.
Libertarians/Communists/Greens/etc: Third parties are at their nadir right now. Zero state or national legislative seats are currently occupied by third parties, which is historically unusual. But increasing the size of Congress would give a shot in the arm to third parties. Getting 25,000 people to vote for you seems much more doable, especially if the whole party goes all-in on one seat. And it only takes one. I gotta believe that the Libertarians could win a Congressional seat in New Hampshire. The Communists could win one in Seattle. And once you get one seat, then it’s off to the races. Getting national recognition as one of 6,641 is really hard - joining or forming a third party is the kind of thing that gets you press. This is speculation, I have no data to back it up, but I fully expect that we would see a big upshot in third party representation and membership. The CAA is exactly what the Libertarians need to break out of their funk.
State legislators: Because you have an opportunity here. The most likely people to be elected to the new Big Congress are those who already have political experience and know what it takes to win an election in a small district. If you vote to ratify the CAA, odds are good that you’ll be among those elected to fill the ranks of Big Congress. And you’ve always wanted to be there in Washington. We both know it.
A Troublesome Typo
The second clause of the amendment describes the situation when the US population is between 3 million and 8 million. It says (my bolding):
There shall be not less than one hundred Representatives, nor less than one Representative for every forty thousand persons
Sounds reasonable enough. This is making the straightforward claim that there should be many representatives, and a high representative-to-constituent ratio.
The third clause of the amendment describes the situation when the US population is greater than 8 million people (i.e. the situation we’re in now). It says:
There shall not be less than two hundred Representatives, nor more than one Representative for every fifty thousand persons.
Notice the non-parallelism with the second clause. The second clause was two less-thans, meaning many representatives and low representative-to-constituent ratio. The third clause is a less-than followed by a more-than, meaning many representatives and a low representative-to-constituent ratio.
Aren’t these two goals - many representatives, and a low representative-to-constituent ratio - in tension?
Yes. In fact, the clause is mathematically impossible to satisfy at populations between eight and ten million. For example, with nine million Americans, we need at least two hundred representatives, but fewer than 9,000,000/50,000 = 180 representatives. Obviously there is no number which is both above 200 and less than 180, so this makes no sense.
At other population sizes, the clause does the opposite of what its founders intended, saying that the legislator-to-constituent ratio should be low and Congress has to be small. For example, at the current US population of 350 million, the clause merely says that Congress must be smaller than 6,641 representatives, meaning that the current Congress size is fine and nothing changes.
The simple explanation is that this is a typo. The people who wrote the law had three clauses, and meant to say “less than . . . less than” in each. But in the third clause, they said “less than . . . more than”. This has been noticed and acknowledged for over two hundred years.
So we have a potential Constitutional amendment which says the opposite of what it definitely means. If passed, this would set us up for a court case that directly pits the legal school of textualism (you need to follow the law as written) against originalism (you need to follow what the people who wrote the law meant). These two schools are often in oblique and complicated conflict. But as far as we know, they’ve never faced so direct a test as a section of the Constitution with an obvious-for-two-hundred-years typo that inverts its meaning. All the Supreme Court Justices who have previously gotten away with talking about how the law is subtle and complicated would have to finally just decide whether textualism or originalism is right, no-take-backs, once and for all. It would be hilarious.
The most likely outcome would be that they would bow to two hundred years of obvious criticism of this incorrectly-worded law, agree that it meant to say that the legislator-to-constituent ratio must be high, and we would get Giant Congress.
But there’s a remote chance that the textualists would win after all. This wouldn’t make things worse - Congress would be constitutionally banned from having more than 6,641 representatives, but this was hardly in the cards anyway. It would also mean that if the US population ever declined to between eight and ten million - admittedly another thing that’s not really in the cards - the Constitution would become logically impossible to follow, and America would officially be a paradox. If the population ever declined to between eight and ten million people, this probably would not be our biggest problem. But it might be the funniest.
The Path To 38
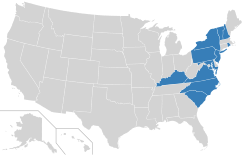
A constitutional amendment must be ratified by 3/4 of states; that’s 38/50. Eleven have ratified it already, so we need 27 more. Of the 39 states that have not ratified the CAA, 13 have legislatures run by Democrats and 25 have legislatures run by Republicans. This has to be a bipartisan effort.
But it’s no worse than the situation with the Twenty-Seventh Amendment. Gregory Watson, the previously mentioned Texas undergraduate, got it passed with $6,000 of his own money and a very dedicated letter-writing campaign. The Congressional Apportionment Amendment may require more work, but the precedent is there.
If you’re a state legislator, or if you know a state legislator, or if you want to be a state legislator after they all move up to Washington, then please introduce a motion to ratify this amendment. And tell all your colleagues that, if they ratify it too, they’ll get to be real Congressmen and Congresswomen. We can have the largest legislative body in the world. We can build monuments again. We can have real third parties again.
Either that, or we’ll turn the Constitution into a paradox and our government will vanish in a puff of logic. Still probably beats what’s going on now.
Of around $67k/year in 2026 dollars.
Under the 2020 census. The number would change upon each subsequent census. In 2030, it will probably be around 6,980.
In case this smacks of cherry-picking, here is a breakdown of the “error” in every state’s Congressional delegation, state house delegation, and state senate delegation. “Error” here is defined as the difference between the representation of each state’s delegation and the percentage of that state that voted for Trump over Harris (or vice versa). In only two states, Florida and Virginia, is the error greatest in the largest body, and both of those states would have Congressional delegations larger than that largest body. In the case of Florida, their delegation would be nearly quadruple the size of their state house.
There could also be an effect from the structure of the TV market. Stations sell ads by region, and each existing media region is larger than the new Congressional districts. So absent a change in market structure, a candidate who wanted to purchase TV advertising couldn’t target their own district easily; they would have to overpay to target a much larger region.
And just to harp on this more, we just blew by the Colorado River Compact agreement deadline and now the federal government is going to start mandating cuts; everybody’s going to sue everybody else. Lake Powell is quite possibly going to dead pool this year, and as far as I can find the congressperson who ran on water issues is saying nothing about it.
This is the weekly visible open thread. Post about anything you want, ask random questions, whatever. ACX has an unofficial subreddit, Discord, and bulletin board, and in-person meetups around the world. Most content is free, some is subscriber only; you can subscribe here. Also:
1: Mox asks me to advertise their 2026 fundraiser. They’re a rationalist/EA coworking space in San Francisco that hosts ACX meetups, ACX grants infrastructure, AI safety work, and more. And while I’m advertising them, they also offer deals on personal and organizational office space.
2: StopTheRace.ai will be holding a protest on Saturday, March 21 in front of major AI company offices, asking them to commit to a mutual pause (ie to stop AI research if every other AI company in the world agrees to do so). Demis Hassabis of Google DeepMind has already informally agreed to something like this in principle (which is why GDM isn’t being protested), and Anthropic has expressed interest but its new responsible scaling policy stops short of an explicit commitment. I think this is a reasonable ask, albeit so unlikely to happen that protests about it will probably do more to raise awareness than be a coherent plan in themselves. If you’re curious about the details of an AI pause, I expect to be able to provide more information in a few months.
3: ACX grantee Markus Englund announces a first set of results from his project to automate anomaly detection in scientific data, finding serious and reportable data issues in eighteen papers, including an influential study linking Parkinson’s to the gut. He plans to scale up his efforts by over an order of magnitude in the year ahead.
California lets interest groups propose measures for the state ballot. Anyone who gathers enough signatures (currently 874,641) can put their hare-brained plans before voters during the next election year.
This year, the big story is the 2026 Billionaire Tax Act, a 5% wealth tax on California’s billionaires. Your views on this will mostly be shaped by whether or not you like taxing the rich, but opponents have argued that it’s an especially poorly written proposal:
It includes a tax on “unrealized gains”, like a founder’s share of a private company which hasn’t been sold yet. This could be an existential threat to the Silicon Valley model of building startups that are worth billions on paper before their founders see any cash. Since most billionaires keep most of their wealth in stocks, any wealth tax will need some way to reach these (cf. complaints about the “buy, borrow, die” strategy for avoiding taxation). But there are better ways to do this (for example, taxing at liquidation and treating death as a virtual liquidation event), other wealth tax proposals have included these, and the California proposal doesn’t.
It appears to value company stakes by voting rights rather than ownership, so a typical founder who maintains control of their company despite dilution might see themselves taxed for more than they have. Garry Tan explains the math here with reference to Google. However, Current Affairs has a good article (?!) that pushes back, saying the proposal exempts public companies like Google. Although private companies would still be affected, this would be so obviously unfair that founders would easily win an exemption based on a provision allowing them to appeal nonsensical results. Still, some might counterobject that proposed legislation is generally supposed to be good, rather than so bad that its victims will easily win on appeal.
It’s retroactive, applying to billionaires who lived in California in January, even though it won’t come to a vote until November. Proponents argue that this is necessary to prevent billionaire flight; opponents point out that alternatively, billionaires could flee before the tax even passes (as some have already done). One plausible result is that the tax fails (either at the ballot box or the courts), but only after spurring California’s richest taxpayers to flee, leading to a net decrease in revenue.
Some people propose that it could decrease state revenues overall even if it passed, if it drove out enough billionaires, though others disagree.
Pro-tech-industry newsletter Pirate Wires finds that 20 out of 21 California tech billionaires interviewed were “developing an exit plan” and quotes an insider saying that “if this tax actually passes, I think the technology industry kind of has to leave the state”. Even Gavin Newsom, hardly known for being an anti-tax conservative, has argued that it “makes no sense” and “would be really damaging”.
The ACX legal and economic analysis team (Claude, GPT, and Gemini) doubt the direst warnings, but agree that the tax is of dubious value and its provisions poorly suited to Silicon Valley.
On one level, it’s no surprise that California, a state full of bad socialists, is considering bad socialist policy. But I think this is the wrong perspective. This proposition isn’t being sponsored by some generic group of Piketty-reading leftists. It’s the project of SEIU (Service Employees International Union) a union of mostly healthcare workers.
This immediately clarifies the debate about whether it’s net negative for revenue. 90% of the revenue from the tax is earmarked for health care. So even if it’s net negative for the state, it isn’t net negative for the health care budget in particular, ie for the people who are sponsoring the measure.
But we can get even more conspiratorial. The SEIU is known in California political circles for pioneering and perfecting the art of extortion via ballot initiative. Their usual strategy goes:
Propose a ballot initiative that will sound nice to voters, but which is actually deliberately designed to ruin some industry.
Demand concessions from that industry in exchange for withdrawing the initiative.
Their first extortion attempt (as far as I know) was the 2014 Fair Healthcare Pricing Act, which would have capped the amount hospitals were allowed to charge for procedures at some unsustainable amount. The hospital association seemed to think this was an existential threat:
If the initiatives are approved by the voters, hospitals could not operate as they do now. It would be necessary for hospitals to restructure their business model and services provided. Additionally, hospitals would be faced with unprecedented decisions — “Which services must be eliminated or cutback?”; “How can the hospital operate without departmental cross-subsidization?”; and “How can strategic planning be conducted in a world of oppression and uncertainty?”
Although the hospitals themselves might be biased, the government’s mandatory fiscal analysis of the initiative seemed to agree, saying that “about 20 hospitals would change from having positive operating margins to having operating losses before taking into account any strategies these hospitals might implement in response to the measure.”
But “help” was on the way. The SEIU offered to withdraw its initiative in exchange for a $100 million “donation” from hospital lobby groups to one of SEIU’s pet causes, plus the right to expand their union into the affected hospitals. The hospitals caved and gave them what they wanted. The union was surprisingly frank in their celebration:
[Union leader Dave] Regan said that the SEIU-UHW had spent $5 million on [backing the ballot initiatives], but that it paid off handsomely. “For a $5 million investment, we get an $80 million turn to pursue those things,” Regan said. He observed that the CHA would have spent as much as $100 million to defeat the initiatives.
Buoyed by their success, SEIU identified dialysis clinics as their next target, and demanded similar union expansion rights (I can’t find any information about whether they also wanted more cash). The dialysis clinics refused, and so began one of the most shameful chapters in California ballot history: The Eternal Kidney Proposition. SEIU proposed a 2018 ballot proposition to cap dialysis clinic revenues at some unsustainable level. The clinics spent $100 million fighting it, “the most money raised for a campaign like this in California history”, and it failed.
And then it was back! In 2020, SEIU proposed a new packet of regulations for dialysis clinics, all of which probably sounded reasonable to the average voter but which had the overall effect of making them ruinously expensive to operate. The measures were opposed by the California Medical Association (representing doctors), the American Nursing Association (representing nurses), various patients’ groups, and even the NAACP (black people are especially prone to kidney disease, and would be hardest hit). Once again, the clinics spent $100 million getting the message out, and the Californian public rejected it.
And then it was back again! In 2022, SEIU proposed basically the same packet of regulations. All the same groups lined up against, now joined by the Renal Physicians Association, the Renal Physician Assistants’ Association, the National Kidney Association, and various veterans groups (older veterans are also commonly affected by kidney disease, and would also be hard-hit). After wasting another $100 million, the proposition was defeated a third time.
Somewhere in this process, Californians started to wonder what was going on. One dialysis proposition might be happenstance, two might be coincidence, but three was enemy action. In 2020, media nonprofit CalMatters published Good Policy Or Ballot Blackmail?, trying to spread awareness of SEIU’s extortion attempts. It focuses on SEIU leader Dave Regan’s love of the tactic:
[SEIU] sponsored Proposition 23 on the November ballot, which would add new regulations for dialysis clinics. It put a similar measure before voters in 2018, which they rejected. In the last two elections, it’s also sponsored a measure to tax hospitals in the Los Angeles County city of Lynwood, and to cap prices at Stanford hospitals and clinics in several Bay Area Cities.
And that doesn’t count the many initiatives it began working on by collecting signatures but withdrew before they reached the ballot — including a minimum wage initiative in 2016, a pair of measures to limit hospital fees and executive pay in 2014, and two other initiatives to curb hospital bills and expand charity care in 2012.
All told, these campaigns have cost the union at least $43 million, and resulted in no wins on the ballot in California — though union president Dave Regan says they’ve helped make progress in other ways. The practice has earned him a reputation as an aggressive labor leader who uses the initiative process to needle adversaries in the health care profession as he tries to expand membership in his union.
“Dave Regan has made this into a strategy,” said Ken Jacobs, chair of the UC Berkeley Labor Center, which researches unions […]
And on the opinions of other labor leaders:
“There’s great resentment toward him because of his ‘my way or the highway’ kind of way of dealing with other folks,” said Sal Rosselli, who worked with Regan as part of the larger SEIU umbrella union for many years, but now heads the rival National Union of Healthcare Workers.
Regan’s frequent use of ballot measures is “dishonest with voters,” Rosselli said. “He’s not doing it to improve the quality of health care… He’s doing it to gain leverage over the employers for top-down organizing rights.”
Wall Street Journal agreed, and even the more liberal Los Angeles Times described SEIU’s work as “political extortion”.
Given that all of SEIU’s past progressive-sounding legislation has been thinly-disguised extortion attempts, might this one be as well?
The argument against: SEIU is entirely focused on healthcare and doesn’t care about the tech industry.
The argument in favor: Gavin Newsom cares about the tech industry. And SEIU cares about Gavin Newsom. Governor Newsom has been eyeing the Democratic presidential nomination in 2028. He needs a reputation as a Sensible Moderate and plenty of billionaire donors. And there’s a clear path to the latter - as Silicon Valley tires of Trump’s random acts of economic devastation, some tech leaders are starting to regret their flirtation with right-wing populism and wonder whether the other side has a better offer. If everything goes exactly right, he can make it work. Instead, there’s this wealth tax, coming at the worst possible time. Newsom really, really wants it to go away. So, Politico reports, he’s been meeting with SEIU leader Dave Regan to see what’s on offer:
Gavin Newsom and his staff have quietly talked to the champion of a controversial wealth tax proposal seeking an off-ramp to defuse a looming ballot measure fight.
The conversations, reported here for the first time, have occurred intermittently for months as SEIU-UHW’s ballot initiative targeting billionaires migrated from the backrooms of California politics to the center of a raging debate about Silicon Valley and income inequality, sparking tech titans’ wrath and vows to move out of state.
“We’ve been at this for four months,” Newsom said in an interview with POLITICO, describing an “all-hands” effort that has included him meeting one-on-one with SEIU-UHW’s leader, Dave Regan.
A compromise does not appear imminent. A union official cast doubt on the possibility of a deal, saying the two sides do not currently have another meeting scheduled and framing a ballot fight as an inevitability.
My read: rather than a heartfelt attempt at redistribution, this is a heads-I-win-tails-you-lose gambit by the SEIU. If Governor Newsom offers them enough concessions and bribes, they’ll drop the initiative. If not, they’ll carry it through, maybe win, and get billions of dollars of extra health care spending, some of which will flow through to their members. Either way, whatever happens to the rest of the state isn’t their concern.
One critique of capitalism argues that, although in theory it aligns incentives perfectly so that companies should produce things that people want, in practice it also incentivizes the hunt for loopholes: addictive products that can take advantage of seemingly-tiny wedges between what people will buy and what’s good for them. Cigarettes, casinos, payday loans, and social media all demonstrate that these wedges collectively form a multi-trillion dollar niche.
In the same way, SEIU seems to have found a bug in direct democracy: it incentivizes interest groups to search for the most destructive possible ballot initiative that might nevertheless get approved by low-information voters, since this gives them leverage over anyone willing to bribe them into withdrawing their poison pill. Seems like an ignominious end for California’s ballot proposition system.
The Wednesday open threads are usually paid-subscriber only, but I’m making this one public to give people more space to talk about everything going on. Also:
1: The OpenAI/Pentagon situation has evolved since Sunday’s ACX post (“All Lawful Use: Much More Than You Wanted To Know”). For up-to-date analysis of the latest contract, I endorse this LW post from today, on the newest contract: OpenAI’s Surveillance Language Has Many Potential Loopholes And They Can Do Better.
Having Your Own Government Try To Destroy You Is (At Least Temporarily) Good For Business
On Friday, the Pentagon declared AI company Anthropic a “supply chain risk”, a designation never before given to an American firm. This unprecedented move was seen as an attempt to punish, maybe destroy the company. How effective was it?
Anthropic isn’t publicly traded, so we turn to the prediction markets. Ventuals.com has a “perpetual future” on Anthropic stock, a complicated instrument attempting to track the company’s valuation, to be resolved at the IPO. Here’s what they’ve got:
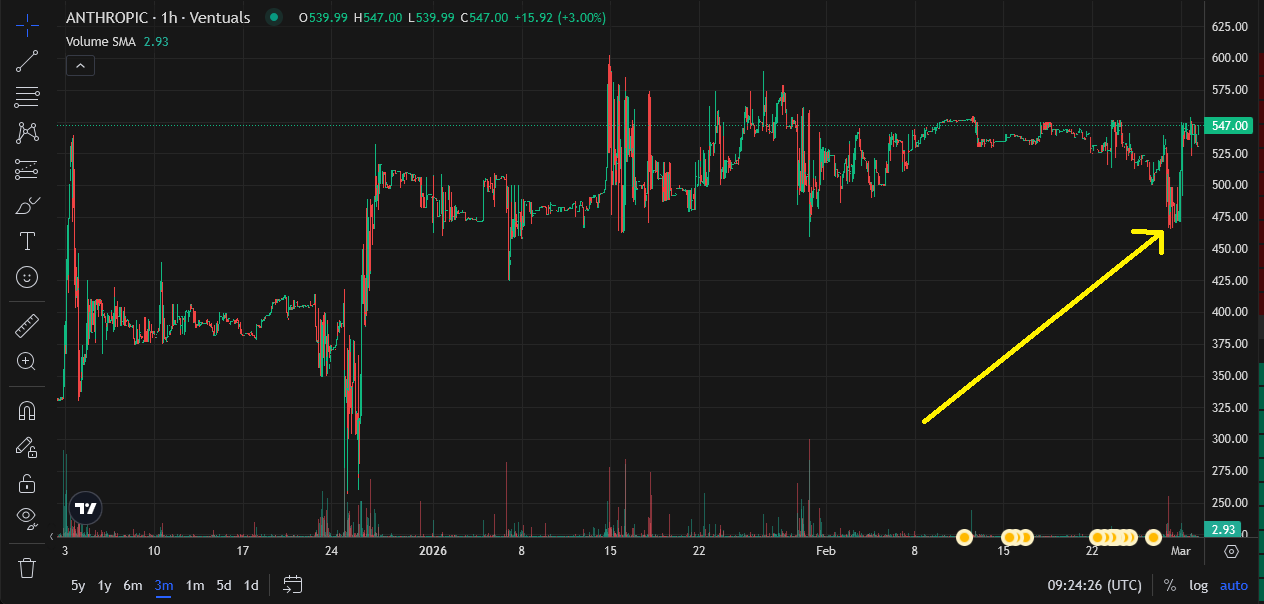
Upon the “supply chain risk” designation, predicted value at IPO fell from about $550 billion to $475 billion - then, after a day or two, went back up to $550 billion. No effect!
A coarser yes-no Polymarket tells the same story:
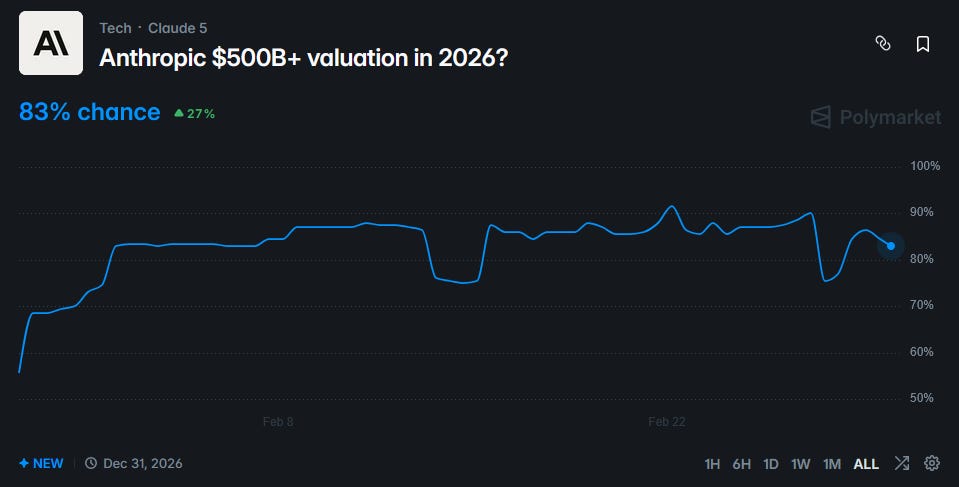
The chance of Anthropic getting a $500 billion+ valuation in 2026 fell from 90% to 76%, before rebounding to 83%.
Why have the markets shrugged off this seemingly important event?
Partly it’s because Anthropic seems likely to win on appeal. Hegseth has said the government will keep using Anthropic for the next six months (undermining his case that they’re a national security risk) and has signed a substantially similar contract with OpenAI (undermining his case that their contract terms were unworkable). The prediction markets think the courts will be sympathetic:
But even in the 28% of timelines where the designation sticks, things don’t seem so bad. Secretary of War Hegseth originally tweeted that:
In conjunction with the President's directive for the Federal Government to cease all use of Anthropic's technology, I am directing the Department of War to designate Anthropic a Supply-Chain Risk to National Security. Effective immediately, no contractor, supplier, or partner that does business with the United States military may conduct any commercial activity with Anthropic.
Framed this way, the Pentagon’s actions sound devastating. Anthropic relies on compute to train and run its AIs. Most of this compute is in data centers owned by Amazon, Google, and Microsoft. At least Amazon and Microsoft have contracts with the US military. If they had to drop Anthropic, it would make it impossible for the company to stay a frontier AI lab.
But in their own blog post, Anthropic described the situation differently:
If you are an individual customer or hold a commercial contract with Anthropic, your access to Claude—through our API, claude.ai, or any of our products—is completely unaffected.
If you are a Department of War contractor, this designation—if formally adopted—would only affect your use of Claude on Department of War contract work. Your use for any other purpose is unaffected.
In other words, the “supply chain risk” designation only means that companies can’t use Anthropic products in their specific Department of War contracts. So if Amazon is doing 95% normal civilian cloud compute stuff, and 5% special government contracts, only 5% of their contracts are affected. This is trivial! Anthropic can keep all its compute and most of its business partnerships even with Department-of-War-linked companies!
The lawyers who weighed in seem to think that Anthropic’s interpretation of the law is correct, and Secretary Hegseth’s interpretation confused. In some situations, this might be cold comfort - how much does it help to be right about the law when the government is wrong? But in this case, it probably helps a lot. Amazon, Google, and Microsoft are all big Anthropic investors - each owns about a 10% stake - and have multi-billion dollar AI compute contracts. Together, the three tech giants must have at least $100 billion riding on Anthropic’s success. They also have good administration connections and great lobbyists, and even Hegseth isn’t stupid enough to pick fights with them all at once. So probably they send their lobbyists to have a talk with Hegseth about what the “supply chain risk” designation actually entails, Hegseth enforces the letter of the law, and Anthropic is barely affected. At least this is the story the prediction markets are going with:
In this best-case scenario, Anthropic’s downside is losing some government contracts that made up ~5% of its business, plus some other Department-of-War-contractor contracts that probably add up to another ~5%.
Against that, the upside is great publicity. Despite a lot of work and some controversial Superbowl ads, Anthropic had never before managed to overcome ChatGPT’s superior name recognition. But they seem to have finally done it: Claude went from #120 on the App Store in January, to #1 this weekend, apparently driven by people who heard about the Pentagon standoff and were impressed by their principled stance.
This could have been a mixed blessing - Anthropic was previously trying to stand out as a B2B company while letting OpenAI have the dubious honor of producing consumerslop. But early signs suggest they might be winning over some companies too. From a Reddit thread on the topic:
As someone who manages IT for a mid-size company, this is actually a big deal. We were evaluating both Claude and ChatGPT for internal use and the Pentagon thing was basically the tipping point for us. Not because we're government adjacent or anything, just because a company willing to walk away from a massive contract on ethical grounds is probably also going to handle our data more carefully than one racing to close every deal possible. The app store ranking makes sense to me.
Finance VP for a mid size tech, we’re moving completely away from ChatGPT/Copilot to Claude.
I’m impressed with the prediction markets here - they’ve taken a bold and counterintuitive stance that I wouldn’t have otherwise considered (that these developments barely harm Anthropic) and made it legible, to the point where I basically believe it.
The Midterms As Potential Crisis
America will hold midterm elections on November 3. Incumbents always have a hard time during midterms, and Trump’s approval rating is low, so it’s expected to be a good year for Democrats. Prediction markets expect them to win at least the House (80% chance) and maybe even the Senate (20 - 40% chance).
This simple story is complicated by two different Republican attempts to change voting law.
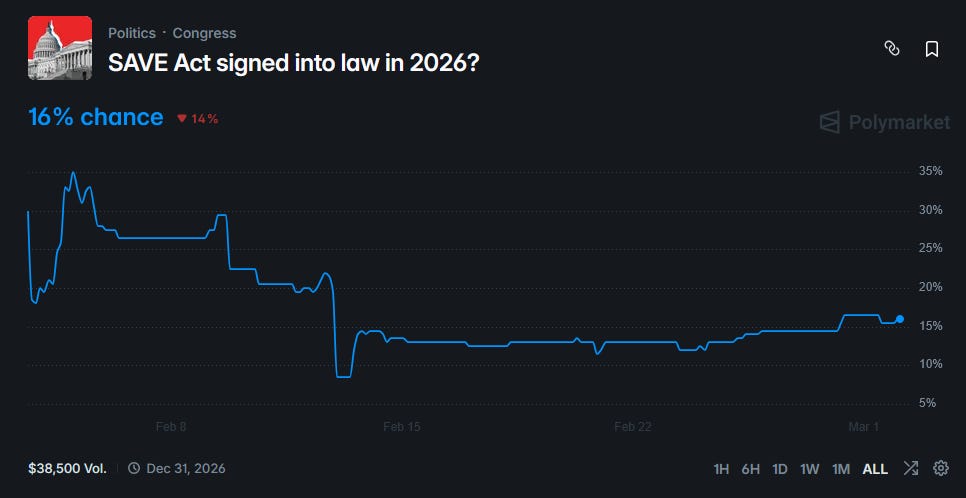
Republicans generally believe there is significant fraud in elections, especially immigrants voting illegally, and propose strict ID requirements to prevent this. Most Democrats believe fraud is rare, and that strict ID requirements are more likely to disenfranchise normal voters who don’t have the right forms of ID available. The latest flashpoint in this battle is the SAVE Act, a Republican-sponsored bill which would require voters to show a passport, birth certificate, or Real ID when registering to vote for the first time or changing their registration. It recently passed the House, but is on track to be filibustered by Democrats in the Senate:
At the same time, there are rumors that the Trump administration is working on an executive order to declare a national emergency and take control of elections. The order would say that foreign countries have been rigging US elections (some commenters speculate that maybe Maduro could be granted clemency for “admitting” to this), and respond with a series of extreme measures. These would include banning voting machines, restricting vote-by-mail, and requiring all voters to re-register before the election. For what it’s worth, Trump has denied all of this, although his previous denial of Project 2025 makes this less reassuring.

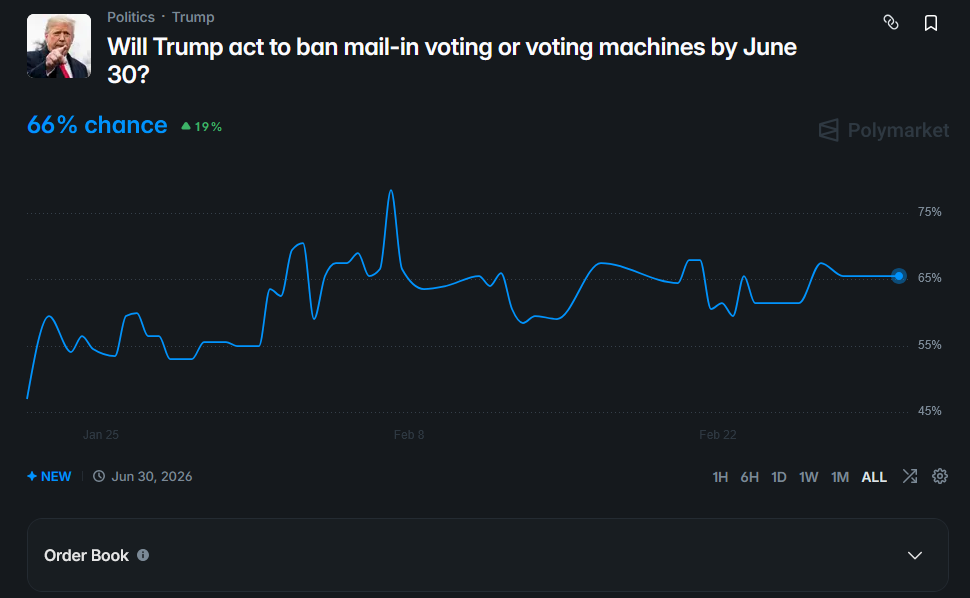
It looks like the markets are saying that Trump will try something, but maybe not the full executive order under discussion.
Most commentators think the EO is unconstitutional, with at least one liberal arguing that it would be good, since it would force the courts to explain exactly how illegal all of this is. But if it somehow made it through the courts, the most likely outcomes could be:
Chaos (at least according to the mostly-liberal commentators I’ve been reading). Do federal agencies really have the capacity to re-register every voter in the next six months (imagine the DMV lines!) Can precincts really switch from voting machines to secure paper ballots during that period? Is there enough supply of the special holographic paper that the order demands for ballots? If not, what happens? Is the election so borked that we can’t figure out who controls Congress? What happens then? At a minimum, lots and lots of court cases.
A blue wave. This would be a somewhat surprising result of Republican policies, but it makes sense. All of these restrictions select for high-information, high-motivation voters - people who hear about the new rules and get fired up enough to hunt down their birth certificate, march down to the DMV, wait on line for one million hours, and re-register. Due to their education advantage and the structural features of midterms, that probably favors Democrats. Democrats are more likely to own passports (one of the easiest forms of valid ID), and less likely to trigger increased scrutiny by having changed their name recently (because liberal women are less likely to marry and take their husband’s surname). First-order, a blue wave like this is good for the left. But second-order, if the above factors lead to some completely implausible blue wave that makes no sense by normal election standards, then Republicans could decide the elections were illegitimate and we’re back at chaos again.
Too many degrees of freedom: Do the Republicans understand the calculus above? One theory is that they plan to make up for it with degrees of freedom. There will be many small decisions about how strictly to enforce each rule, and maybe they’ll be lenient in Republican districts and strict in Democratic ones. The administration is trying to purge potentially fraudulent voters from the rolls - a process with obvious potential for abuse (purged voters can re-register to prove their non-fraudulentness, but this adds an extra layer of complication, so if mostly Democrats get purged, this overall decreases the Democratic voter base). If the administration finds some way to disproportionately disenfranchise Democrats - or if even if Democrats just believe they’ve done this - then Democrats might consider the election results illegitimate, and we would get - again - chaos.
However, courts seem to be blocking all of these measures (except the SAVE Act, which is unlikely to pass Congress). It’s hard to see a world where the really disruptive ones get through. What do the markets say?
This seems like a good sign that there won’t be mass voter disenfranchisement.
But Metaculus expects a 25% chance that martial law is declared?!
In every election he’s been involved in, Trump has either outright said he won’t accept a result that goes against him, or at least given mixed signals about this. In 2020, he took various extreme steps to overturn the election, including telling state officials to throw out ballots, demanding that the count be stopped, trying to get the Vice President to certify fake electors, and the January 6 protests. Will he try the same thing during the midterms? He might not care as much about elections where he’s not personally involved. Or he might use the same playbook, this time with a much more docile Republican party mostly purged of spine-havers like Mike Pence. If he tries this, probably Democrats will protest; if those Democratic protests become unruly, maybe he’ll declare martial law to shut them down. “Chaos” doesn’t even begin to describe this situation.
Maybe the best headline summary of election forecasting are the “free and fair” questions, but they’re hard to interpret.
A Manifold market with 25 forecasters gives a 41% chance that the elections aren’t considered “free and fair”. The resolution criteria is the opinion of international election observers and the mainstream media, who lean liberal. In the past, these observers have sometimes given the US a less-than-perfect verdict - for example, OSCE described the 2024 US election as:
While the general elections in the United States demonstrated the resilience of the country’s democratic institutions, the election process took place in a highly polarized environment. The election was well run, and candidates campaigned freely across the country with the active participation of voters. However, the campaign was marred by disinformation and instances of violence, including harsh and intolerant rhetoric. Repeated, unfounded claims of election fraud negatively impacted public trust.
…and they can probably find even more to complain about in a Trump-run election. Is this sufficient to create uncertainty around the resolution, and drop the probability to 40%? I’m not sure.
But Metaculus has a similar question noting that “This question may resolve as Yes [even] if the EAC, the OSCE, or the Carter Center notes only isolated problems or areas for improvement”, and it’s at 92%, which is reassuring.
I think the best summary of forecasters’ views on the midterms is that there’s a decent chance (~50%) Trump tries to change the rules around mail-in ballots, and a modest chance (~25%) he tries something more extreme - but that it probably won’t make much difference, the election will still be considered fair by international observers, and Democrats will still win.
I’m very interested in creating better prediction markets about the fairness of the 2026 elections. If anyone has ideas for how to do this, let me know.
Groundhog Day
Tweeted by the National Weather Service’s New York City branch:

Punxsutawney Phil, the famous Groundhog Day groundhog, actually has less than 50% accuracy in predicting the length of winter. At what point do we flip the legend and say that there’s more winter if he doesn’t see his shadow?
But wait! Staten Island Chuck has an impressive 85% accuracy! The graphic says “since 1981”, which would imply 45 years of prognostication, but it looks like their source is this site, which only counts the last twenty years of data. That would also match the percent, since 85% of 20 is a round 17. In a separate analysis of 32 years, the Staten Island Zoo accords him an 81% success rate. That’s p = 0.0002 - plenty significant even after a Bonferroni correction for multiple magic groundhogs.
So is the groundhog legend true? Seems like it can’t be - the legend originated with Punxsutawney Phil, who does worse than chance. What kind of crazy Gettier case would we have to believe in to have the original magic groundhog be a fraud but, coincidentally, have another groundhog a few hundred miles away be actual magic?
A more prosaic explanation is that, according to this site, Staten Island Chuck is almost a broken clock, predicting spring on 25/31 occasions. If early springs are more common than long winters on Staten Island, that fully explains the phenomenon. It could equally well explain Mojave Max, the legendary anti-oracular tortoise of Las Vegas, who has managed a 20% success rate over decades on what ought to be a coin flip - he won’t stop predicting long winter, and is nearly always wrong.
Iran Warcasting
Speaking of Groundhog Day, we’re bombing the Middle East again. Here’s what the markets have to say:
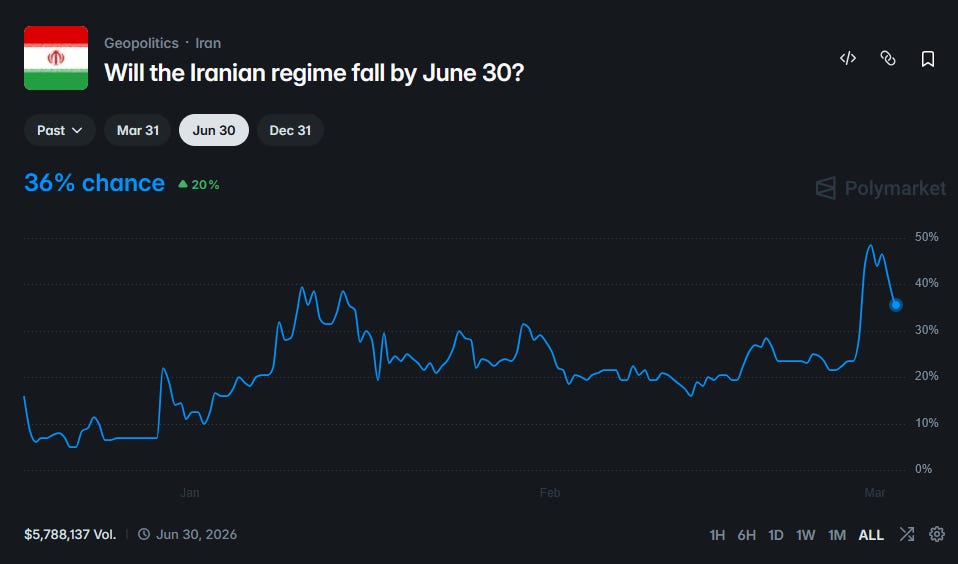
These two well-behaved markets agree on a somewhat less than 50-50 chance that the current round of airstrikes topple the Iranian regime.
Alireza Arafi, a hardline cleric with no distinguishing characteristics, is weakly favored to succeed Khameini as Supreme Leader. Other contenders include Khomeini’s grandson and Khameini’s son, and there is a 15% chance that they abolish the position before figuring out a successor.
The Strait of Hormuz is the waterway between Iran and Arabia that many of the world’s oil tanker routes pass through. Iran is already threatening traffic in the strait; if it threatened it more, it might be able to damage the global economy. This wouldn’t really help anything - Iran is part of the global economy too - but it would probably feel good to annoy the US a little more than they could otherwise do. Realistically this all comes down to the resolution criteria - Iran will certainly threaten the Strait, but probably can’t keep it 100% closed forever. The criteria here specify decreasing a seven-day moving average of traffic to below 20% of its usual level, which forecasters seem to think is more likely than not.
Manifold expects between 6 - 100 US casualties.
Polymarket thinks the war will be over by March 31, but…
…a Manifold market leaves some probability on it continuing until January (or perhaps restarting by then). Gotta say, I’m not seeing this one.
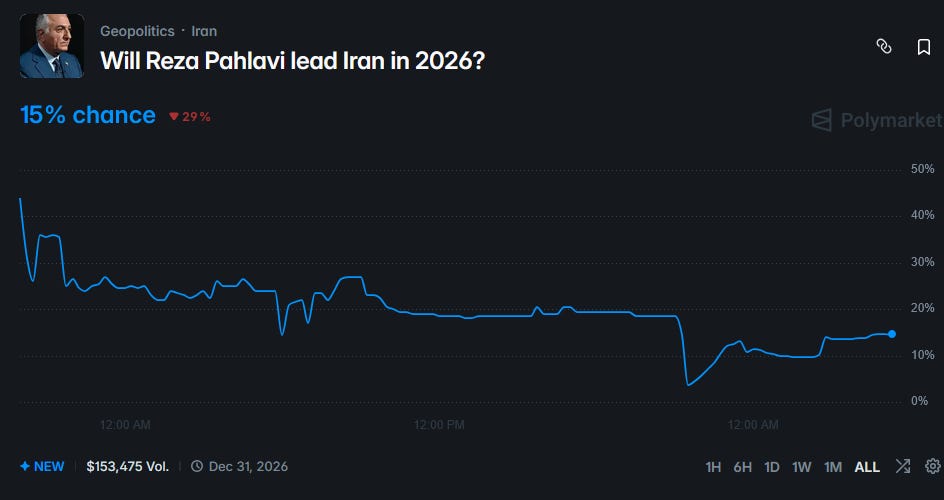
Reza Pahlavi is the heir of the Shahs of Iran. Polymarket thinks that if the current regime falls, there’s about a 40% chance they’ll reinstate the monarchy.
I found this Marginal Revolution post helpful in making sense of the markets’ view on Iran. America hoped that killing the Ayatollah would provoke mass protests and make the regime collapse. That doesn’t seem to have happened, and the regime seems ready to appoint a new Supreme Leader and keep going. America’s strategy will be to keep killing as many higher-ups as possible and bombing Iranian military sites, in the hopes that eventually the populace rises up or the remaining ayatollahs fail to hash out a succession plan. Iran’s strategy will be to just try to hold on, and cause enough pain for America and its allies that the US goes away sooner rather than later. Most likely America will either win or give up within a month, but there’s a long tail of outcomes with continued conflict until potentially as late as next year.
MNX
Stephen Grugett and Ian Philips of Manifold Markets have announced a new project, MNX.
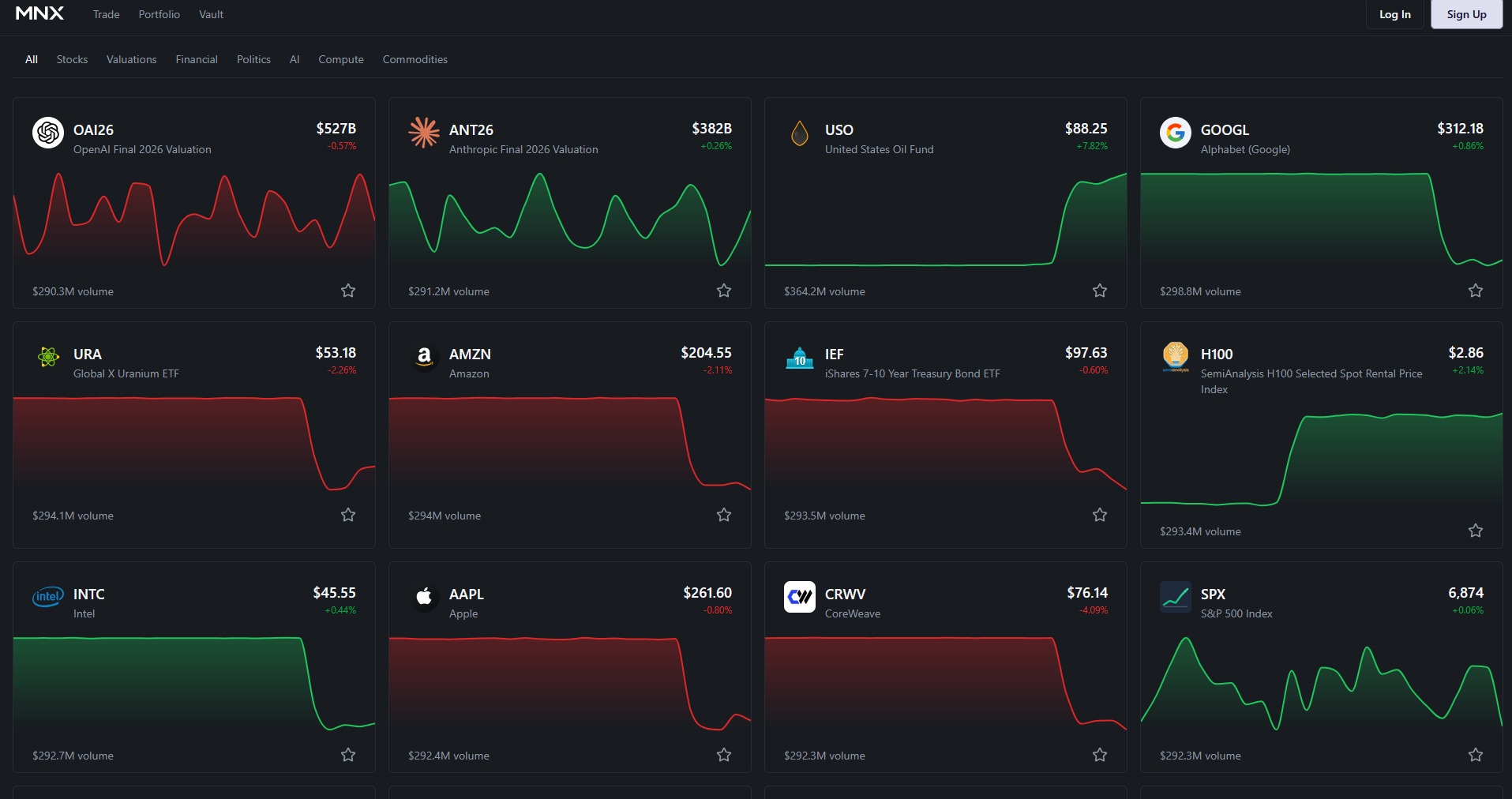
MNX is a noncustodial cryptocurrency-based futures exchange offering financial products relating to AI, including some prediction-market-shaped ones. For example, ECI26 lets users place bets on the highest score that an AI will attain on the Epoch Capabilities Index by the end of the year.
Manifold is a great site, and I challenged Grugett on why he’s starting a new project. His answer: hedging. I didn’t transcribe all the details, but that’s fine, because Vitalik coincidentally wrote a pro-hedging manifesto last week.
Recently I have been starting to worry about the state of prediction markets, in their current form. They have achieved a certain level of success: market volume is high enough to make meaningful bets and have a full-time job as a trader, and they often prove useful as a supplement to other forms of news media. But also, they seem to be over-converging to an unhealthy product market fit: embracing short-term cryptocurrency price bets, sports betting, and other similar things that have dopamine value but not any kind of long-term fulfillment or societal information value. My guess is that teams feel motivated to capitulate to these things because they bring in large revenue during a bear market where people are desperate - an understandable motive, but one that leads to corposlop.
I have been thinking about how we can help get prediction markets out of this rut. My current view is that we should try harder to push them into a totally different use case: hedging, in a very generalized sense (TLDR: we're gonna replace fiat currency)
Prediction markets have two types of actors: (i) "smart traders" who provide information to the market, and earn money, and necessarily (ii) some kind of actor who loses money.
But who would be willing to lose money and keep coming back? There are basically three answers to this question:
1. "Naive traders": people with dumb opinions who bet on totally wrong things
2. "Info buyers": people who set up money-losing automated market makers, to motivate people to trade on markets to help the info buyer learn information they do not know.
3. "Hedgers": people who are -EV in a linear sense, but who use the market as insurance, reducing their risk.(1) is where we are today. IMO there is nothing fundamentally morally wrong with taking money from people with dumb opinions. But there still is something fundamentally "cursed" about relying on this too much. It gives the platform the incentive to seek out traders with dumb opinions, and create a public brand and community that encourages dumb opinions to get more people to come in. This is the slide to corposlop.
(2) has always been the idealistic hope of people like Robin Hanson. However, info buying has a public goods problem: you pay for the info, but everyone in the world gets it, including those who don't pay. There are limited cases where it makes sense for one org to pay (esp. decision markets), but even there, it seems likely that the market volumes achieved with that strategy will not be too high.
This gets us to (3). Suppose that you have shares in a biotech company. It's public knowledge that the Purple Party is better for biotech than the Yellow Party. So if you buy a prediction market share betting that the Yellow Party will win the next election, on average, you are reducing your risk.
(mathematical example: suppose that if Purple wins, the share price will be a dice roll between [80...120], and if Yellow wins, it's between [60...100]. If you make a size $10 bet that Yellow will win, your earnings become equivalent to a dice roll between [70...110] in both cases. Taking a logarithmic model of utility, this risk reduction is worth $0.58.)
See the tweet for more, including a suggestion that “the real solution [might be] to go a step further, and get rid of the concept of currency altogether”.
MNX will not be getting rid of the concept of currency altogether. Their vision of a hedge market relies on some more prosaic beliefs.
First, that Polymarket and Kalshi are doing a good job filling the gambling niche, Metaculus is doing a good job filling the information-aggregation niche, and hedging is the last prediction market niche capable of spawning a billion-dollar company. Actually, why set your sights so low? There’s currently two trillion dollars tied up in the derivatives market; a better hedge would be very lucrative.
Second, that hedging is about to enter a renaissance. Even sophisticated hedge funds only hedge a few types of risk, because nobody wants to spend hundreds of hours sculpting a hedge portfolio that catches 99.99% of possibilities and changing it every few days as the market shifts form. But if the Agent Economy Of The Future brings the cost of intellectual labor down near zero, then there’s no reason not to do that. If you invest in a seaside resort, your AI can figure out the chance of a hurricane, and of a tsunami, and of an oil spill, and of a thousand other things, and buy a tiny share of each on the prediction markets, and feel confident that you’re expressing your exact thesis (seaside resorts are good) separate from any acts of God that might disturb it.
Third, the past few years have seen dramatic advances in financial technology. Crypto traders have invented the perpetual future, a new instrument that tracks an asset without requiring anyone to own the asset involved. That means traders can buy and sell shares of SpaceX, OpenAI, and other nonpublic companies that won’t actually give you their shares. Hedging the price of nickel used to require someone somewhere in the process to own an actual warehouse full of nickel. Now you can skip that step.
(the other technological sea change is that this is possible at all. Five years ago, cryptocurrency prediction markets were too complicated. In the late 2010s, a group called Augur raised $5 million for the project but never managed to create usable software. FTX flirted with prediction-like contracts but never got them off the ground even with all their billions. Polymarket was the first to really solve this, making $10 billion in the process, but even they were barely usable in the early days. But Stephen’s making MNX with his own money and a team of 1-2 people. He benefits partly from the vibecoding revolution, and partly from all of the billions of dollars spent on improving cryptocurrency rails - MNX uses the stablecoin USDC).
MNX is focusing on AI for now, because it’s buzzy and there’s lots of money flowing into it. But if goes well, it could one day expand to seaside resorts, nickel, and everything else.
Elsewhere In Prediction Markets
1: CEO Chris Best reports that Substack is partnering with Polymarket to make it easier to embed prediction markets in Substack posts and notes. I haven’t been using the embeds here because they don’t let you see the history graph, but I’m excited about them in general. And his post also mentions that “one in five of Substack’s top 250 highest-revenue publications [has] started using [prediction markets]”, which surprises me but seems like a great sign.
2: Yahoo Finance: Man Bet Entire Life Savings Of $342,195 That Elon Musk Would Fail. This is more heartwarming than it sounds - it’s about economist Alan Cole and a Kalshi market about whether DOGE would successfully cut the federal budget by some amount. Cole was an expert in tax law and knew that the budget is sufficiently constrained that it was literally impossible to cut it that amount, and so (after getting his wife’s buy-in) put his entire life savings on NO. NO turned out correct, netting him a 37% profit after one year.
3: This Matt Yglesias tweet is more interesting than it sounds:
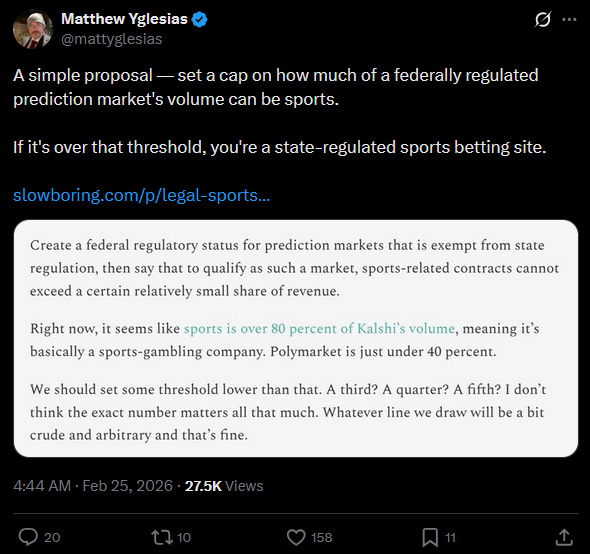
If this were enacted, the winning play would be for platforms to subsidize their non-sports markets with the profits from their sports markets, in order to win the right to have as many sports markets as possible. These subsidies would turn non-sports prediction markets from zero-to-slightly-negative-sum (because your gains are always a counterparty’s losses, minus fees) to positive-sum (because everyone is taking the platform’s subsidies). Yglesias has discovered a solution to one of the oldest problems in the space - how to incentivize the public good of prediction market participation!
Too bad the government will never do this.
This is the weekly visible open thread. Post about anything you want, ask random questions, whatever. ACX has an unofficial subreddit, Discord, and bulletin board, and in-person meetups around the world. Most content is free, some is subscriber only; you can subscribe here. Also:
1: ACX Grantee Stephen Grugett (of Manifold Markets) wants me to announce his latest project: MNX, “a decentralized futures exchange targeting sophisticated traders and focused on the AI economy”. It’s a real-money platform where traders who want to hedge their AI plays can bet on benchmark progress, compute prices, etc. Announcement here, testnet here.
2: I think I got my tone wrong on last week’s Open Thread and made people think I was condemning the Harper’s article that mentioned me. I actually liked it and was just trying to clarify a few points. Please don’t get angry about it on my behalf. So as to not make things worse, I’ll banish further discussion of this to a comment.
Last Friday, Secretary of War Pete Hegseth declared AI company Anthropic a “supply chain risk”, the first time this designation has ever been applied to a US company. The trigger for the move was Anthropic’s refusal to allow the Department of War to use their AIs for mass surveillance and autonomous weapons.
A few hours later, Hegseth and Sam Altman declared an agreement-in-principle for OpenAI’s models to be used in the niche vacated by Anthropic. Altman stated that he had received guarantees that OpenAI’s models wouldn’t be used for mass surveillance or autonomous weapons either, but given Hegseth’s unwillingness to concede these points with Anthropic, observers speculated that the safeguards in Altman’s contract must be weaker or, in a worst-case scenario, completely toothless.
The debate centers on the Department of War’s demand that AIs be permitted for “all lawful use”. Anthropic worried that mass surveillance and autonomous weaponry would de facto fall in this category; Hegseth and Altman have tried to reassure the public that they won’t, and the parts of their agreement that have leaked to the public cite the statutes that Altman expects to constrain this category. Altman’s initial statement seemed to suggest additional prohibitions, but on a closer read, provides little tangible evidence of meaningful further restrictions.
Some alert ACX readers1 have done a deep dive into national security law to try to untangle the situation. Their conclusion mirrors that of Anthropic and the majority of Twitter commenters: this is not enough. Current laws against domestic mass surveillance and autonomous weapons have wide loopholes in practice. Further, many of the rules which do exist can be changed by the Department of War at any time. Although OpenAI’s national security lead said that “we intended [the phrase ‘all lawful use’] to mean [according to the law] at the time the contract is signed’, this is not how contract law usually works, and not how the provision is likely to be enforced2. Therefore, these guarantees are not helpful.
[EDIT: To clarify: The DoW can change their own policies at will, but can’t change laws. In addition to OpenAI’s claim of being robust to changing laws, OpenAI argues that they’re protected against changes to DoW policies because they explicitly reference the relevant policies as they exist today. Based on public information, this argument seems dubious. See ‘Comments on OpenAI’s FAQ’ below.]
To learn more about the details, let’s look at the law:
Mass domestic surveillance: more than you wanted to know
Mass and targeted surveillance of foreigners in their foreign countries is legal. Broadly, the courts have declined to grant standing to allow court cases to test the Executive Branch’s position that the President has inherent powers derived from his constitutional role to authorize foreign intelligence and counterintelligence surveillance, which de facto has allowed this position to become the standard Executive Branch argument for lawfulness.
Targeted surveillance of Americans domestically is legal for domestic law enforcement purposes and (in narrow and usually time-limited cases) for intelligence and counterterrorism. The surveilling agency must get the permission of a court first: normal courts for law enforcement, the Foreign Intelligence Surveillance Act (FISA) court for intelligence. This latter category includes things like wiretapping Americans suspected of spying for Russia.
Mass domestic surveillance of Americans, American companies, and US permanent residents (or for that matter generally their counterparts in other Five Eyes partners – UK, Canada, Australia, and New Zealand) is more complicated. The current law is (roughly) that it’s illegal to seek this kind of data, but legal to “incidentally obtain” it. So for example, if the US was looking for al-Qaeda communications, it might tap a major undersea cable, and if tapping that cable happened to incidentally give it data on millions of Americans, it could keep that data. But after “incidentally obtaining” the data, it may only query the resulting database in a targeted way. So the government might take its trove of citizen data that it “incidentally” collected looking for al-Qaeda, and search for a specific citizen’s history if it thinks (for example) that this citizen might be a spy.
The government reserves the term “mass domestic surveillance” for the thing they don’t do (querying their databases en masse), preferring terms like “gathering” for what they do do (creating the databases en masse). They also reserve the term “collecting” for the querying process - so that when asked “Does the NSA collect any type of data at all on millions or hundreds of millions of Americans?”, a Director of National Intelligence said “no” under oath, even though, by the ordinary meaning of this question, it absolutely does.
(It’s worth noting that the NSA is a DoW agency3).
Mass analysis of third-party data is also legal! That is, if they buy the data from some company - let’s say Facebook - they can do whatever they want with it. The main enforceable exception is certain kinds of cell phone location data, which were carved out in a 2018 Supreme Court case.
Whatever the President thinks is legal may also, in certain cases, be legal. During the War on Terror, President George W. Bush’s Office of Legal Counsel claimed that he also had the inherent constitutional power as President to lawfully authorize warrantless mass collection of internet metadata and telephone call records, a dragnet scooping up Americans and non-Americans’ data alike. The program was initially justified by counterterrorism, but was far more expansive4. This was such a scandal within the US government that many DOJ officials threatened to resign; even DOJ officials who didn’t know what was going on threatened to resign because they assumed it was so bad. Later, the program was moved under statutory and FISA Court frameworks, until finally Congress ended it by passing the USA FREEDOM Act.
So why should we be concerned about even “lawful use” of AIs for surveillance? There are stories about each of these categories, but the most compelling is that the government can buy data from third parties (eg tech companies, cell phone companies) and surveil it as much as they want. In the past, the strongest disincentive was scale and cost: you simply cannot look through every text message sent over the course of a month to see which ones mention a certain dissident. There are hacks - you can perform an automated search for the dissident’s name - but also obvious ways around the hack (the dissident can simply not mention their own name in plain text). AI solves these scale and cost problems. An AI could perform meaningful search of all messages in a large database, piecing together patterns to, for example, give each citizen a “presumed loyalty” score.
This is currently a “lawful use” of AI, and one of the ones Dario Amodei’s letter says that he’s worried about. As far as we can tell, Altman’s contract with the Department of War doesn’t contain any provisions preventing them from using ChatGPT this way.
For more details on mass domestic surveillance: see this doc.
Autonomous weapons: more than you wanted to know
Let’s now turn to autonomous weapons. (The authors of this section are not themselves experts, but they consulted with an expert in national security law.)
There is hard Congressional law regulating the use of armed force in general (for example, you’re not allowed to shoot innocent Americans.) But to our knowledge, autonomous weapons in particular are only regulated by Department of War policy - in particular DoD Directive 3000.09. These policies don’t impose meaningful constraints, for two reasons.
First, the policies are vague. Directive 3000.09 requires that autonomous weapon systems be designed to “allow commanders and operators to exercise appropriate levels of human judgment over the use of force.” But it doesn’t define “appropriate”, and the US government has stated it “is a flexible term” where what qualifies “can differ across weapon systems, domains of warfare, types of warfare, operational contexts, and even across different functions in a weapon system.” The institution that decides what’s “appropriate” is the same institution that wants to use the weapon.
Second, the Department of War can change its own policies, so any contract which only guarantees “lawful use” rather than hard-coding some particular standard gives the DoW complete latitude to change the relevant directive (and therefore the terms) whenever they want5.
Everyone (including Anthropic) agrees that some form of autonomous weapons will be necessary to win the wars of the future - indeed, autonomous weapons are already being used on the battlefield in Ukraine. But there’s a wide spectrum from humans-entirely-in-the-loop to humans-partly-in-the-loop to humans-totally-unrelated-to-the-loop, and we might want humans involved somewhere for at least two reasons.
First, humans add reliability. For the same reason that chatbots sometimes hallucinate, and coding agents sometimes make crazy and reckless decisions that no human would consider, fully autonomous weapons might make inexplicable mistakes in their use of lethal force, with potentially devastating results.
Second, and more important, human soldiers are a check on the worst abuses of authoritarians. Sometimes a strongman will give an illegal order - to shoot at protesters, to initiate an auto-coup, to begin a genocide - and soldiers will say no. Sometimes those soldiers will decide that the appropriate response is to arrest the strongman instead. However often this happens, the fear of it keeps strongmen in line and forces them to consider public opinion at least insofar as the army is made up of the public. If there’s a fully robotic force that automatically obeys orders, this check disappears.
Some types of fully autonomous weapons are clearly appropriate today (e.g. some missile defences for Navy ships). Many more will plausibly have to be developed in the future, especially if other countries pursue them. But a good system of checks and balances for them does not yet exist. AI companies should take care to not sign a contract that could require them to build systems without adequate safeguards, akin to the safeguards of a soldier’s judgement and respect for the Constitution6.
For more details on autonomous weapons, see this doc.
Comments on OpenAI’s FAQ
OpenAI provided an FAQ, which we think is misleading. While we aren’t lawyers, we’ve done our best to lay out our reasoning for this belief, and have also consulted with an expert in national security law on the excerpt of the contract provided in OpenAI’s announcement, and checked that their views were consistent with ours.
Will this deal enable the Department of War to use OpenAI models to power autonomous weapons?
No. Based on our safety stack, our cloud-only deployment, the contract language, and existing laws, regulation and policy, we are confident that this cannot happen. We will also have OpenAI personnel in the loop for additional assurance.
Since the law straightforwardly permits autonomous weapons, and the contract permits any autonomous weapons allowed by the law, the “contract language, and existing laws, regulation and policy” does nothing to prohibit this. OpenAI hasn’t shared enough information about their safety stack for us to be able to evaluate that claim. See below for comments on cloud-only deployment.
Our national security law expert was also very skeptical of the idea that the DoW would have OpenAI personnel meaningfully “in the loop” in sensitive contexts.
Will this deal enable the Department of War to use OpenAI models to conduct mass surveillance on U.S. persons?
No. Based on our safety stack, the contract language, and existing laws that heavily restrict DoW from domestic surveillance, we are confident that this cannot happen. We will also have OpenAI personnel in the loop for additional assurance.
The law does significantly restrict domestic mass surveillance but, as explained above, leaves loopholes that may concern many readers. Since the contract permits any surveillance allowed by the law, the contract itself does nothing further to restrict the DoW from domestic surveillance. OpenAI hasn’t shared enough information about their safety stack for us to be able to evaluate that claim.
What if the government just changes the law or existing DoW policies?
Our contract explicitly references the surveillance and autonomous weapons laws and policies as they exist today, so that even if those laws or policies change in the future, use of our systems must still remain aligned with the current standards reflected in the agreement.
It is not the case that the contract consistently references current laws. The first clause says “The Department of War may use the AI System for all lawful purposes, consistent with applicable law, operational requirements, and well-established safety and oversight protocols.” Our understanding is that later clauses do not automatically override this first clause.
OpenAI’s Head of National Security Partnerships has said “we intended it to mean ‘the law applicable at the time the contract is signed’”, and their CSO has also made a similar statement. Our understanding is that this is a highly non-standard interpretation. The national security law expert we consulted agreed, and was very skeptical that the allowed and required activities would remain the same if the law changed (see also here, starting from “If OpenAI is just referencing...)
(EDIT 03/02/2026: A few clarifications about this:
We haven’t seen most of the contract. It’s possible that other parts of the contract stipulate OpenAI’s interpretation of “applicable law”.7
The FAQ quote above states that the contract “explicitly references the surveillance and autonomous law policies *as they exist today*“ (bold in original). From reading the contract excerpt, it’s not clear what is supposed to make this explicit. Perhaps it is the “date stamps” that OpenAI’s Chief Strategy Officer Jason Kwon mentions in his reply here, but this is confusing for two reasons, see footnote8.
We’d like to clarify the argument for why references to existing laws and policies may not be sufficient to freeze the terms in place if the law or policies change. Above, we wrote that “later clauses [about specific laws and policies] do not automatically override this first clause [allowing ‘all lawful purposes’]”. This isn’t wrong, but we think there are more relevant arguments, like those offered by former general counsel of the Army Brad Carson, who is confident that the quoted contract language doesn’t freeze federal law in the way OpenAI wants. See footnote for details)9
How do you address the arguments Anthropic made in their blog post about their discussion with the DoW?
(...) Below is why we believe those same red lines would hold in our contract: (...) Fully autonomous weapons. The cloud deployment surface covered in our contract would not permit powering fully autonomous weapons, as this would require edge deployment.
Autonomous weapons can be steered by an AI in the cloud, just like a human can steer a drone remotely. OpenAI models do not need to be edge deployed in order to power a fully autonomous weapon.
Overall: We can’t see how any of OpenAI’s claimed methods for enforcing their red lines would work except possibly if they’re allowed to implement technical safeguards that block certain lawful use, which they’ve shared so little about that we can’t evaluate it. Boaz Barak suggests this is the case. If this is right, it’s strange that they don’t elsewhere stress this as the linchpin of their approach, or show the part of the agreement that guarantees them this ability. Further clarification on this point would be very helpful.
Questions that you should be asking
If you have access to OpenAI or DoW decision-makers as an employee, journalist, or lawmaker, these are questions you should be asking:
Immediate questions about the contract.
First and foremost: Ask to see the full contract, as much as you can get. Scrutinize it yourself or run it by a lawyer in a conversation where attorney-client privilege exists (basically, when you are talking with them for the explicitly-stated intent of potentially securing their legal counsel, or once you’ve formally secured them as your legal counsel).
Beyond that:
Does OpenAI’s definition of fully autonomous weapons include non-edge deployed systems like drones operated remotely by AI systems in the cloud? If so, what prevents the DoW from using OpenAI models in this way?
The DoW has been insistent that private companies shouldn’t dictate how the DoW can use models. OpenAI says they “retain full control over the safety stack we deploy”. How are these compatible? Can you share an excerpt from the agreement that describes OpenAI’s control over the safety stack?
Would OpenAI’s models assist with bulk analysis of Americans’ data purchased from third parties?
Will OpenAI’s technical safeguards intentionally block any lawful usage that goes against your red lines?
Who determines if use is “unlawful”? Does OpenAI have recourse if it believes use is unlawful but the DoW disagrees?
What “technical safeguards” have been agreed upon? What happens if the DoW and OpenAI disagree about what version of these safeguards are appropriate?
Does the DoW have options for recourse if OpenAI provides systems with safeguards that the DoW think unduly reduces model performance for specific lawful purposes?
Does the agreement specify that the NSA and other intelligence agencies inside of the DoW are excluded from being able to access OpenAI models?
Broader questions about the situation:
What prevents the DoW from later demanding these restrictions be loosened, as it did with Anthropic?
What recourse does OpenAI have if DoW violates the terms of a contract with OpenAI?
What would stop the DoW from retaliating against OpenAI, as they did with Anthropic, if the DoW and OpenAI have disagreements in the future?
Given that existing statements haven’t always been clear and Anthropic has alleged that the contract contains “legalese that would allow those safeguards to be disregarded at will”, we encourage you to read any responses you receive with a skeptical mindset, and ask yourself whether the response is consistent with OpenAI models being used for autonomous weapons systems or domestic mass surveillance in the colloquial sense of the terms.
They wish to remain anonymous, but none are employees of any major AI lab or the Department of War.
For more, see the section ‘Comments on OpenAI’s FAQ’
OpenAI’s head of National Security Partnerships has made a few unclear tweets perhaps implying that NSA might be excluded from their contract. However, as of this writing, they have not clearly confirmed this, have made some other statements that all of DoW (which includes NSA) is in scope of their contract, and have not made any comment on other DoW intelligence agencies (there are 8 others). It would be great to get further clarification on this point.
To be fair, there are some genuine technical reasons for this – because of how traffic routes across the internet’s logical and physical structure, the government correctly notes that it’s often hard to know before grabbing them whether a given set of internet packets is related to a foreign intelligence query or not – but members of both parties and nonpartisan Inspectors General have repeatedly identified how this technical decision has enabled abuses.
OpenAI suggests they’re protected against this since their agreement specifically refers to “DoD Directive 3000.09 (dated 25 January 2023)”. But other parts of the contract refers to “all lawful purposes” without specifying current law in particular, which would at-best lead to contradictions if the law changes. More on this below.
These safeguards might initially have to be broader than legal use, since current law is not yet designed with powerful autonomous systems in mind
However, when directly asked, OpenAI's Chief Strategy Officer doesn't refer to other parts of the contract but instead says that OpenAI's interpretation is supported due to the use of "date stamps". This is confusing, since the question was about the term "applicable law", which is not itself date stamped. It's possible Kwon misunderstood the question.
First, because later replies cast doubt on Kwon’s claims about how standard his interpretation is. Second, because only one of the laws and policies mentioned in the contract excerpt is date stamped. (Some of the laws mention specific years, but only when the year is included in the name of that law.)
Why was our argument not the most relevant argument? While it's true that later clauses (on specific laws and policies) don't automatically take precedence over the first clause (about “all lawful purposes”), it's also true that the first clause doesn't automatically take precedence over later clauses. All clauses matter for interpreting the overall contract. In fact, there's a general principle that more specific clauses tend to take precedence over more general clauses. This could make for a plausible argument that clauses which reference specific laws and policies take precedence over the general clause allowing "all lawful purposes". However, another interpretation would be that the references to specific laws and policies refer to the most up-to-date versions of the named laws and policies, rather than treating them as frozen into place. This would reduce conflict with the "all lawful purposes" clause, and it might therefore get some support from the inclusion of the "all lawful purposes" clause. But even if that wasn't there, this latter interpretation would still be strongly favored according to Brad Carson (former general counsel of the Army, former undersecretary of the Army, former undersecretary of Defense), unless OpenAI has explicit language to the contrary. Given his expertise, and given that he agrees on the bottom line with the national security law expert that we consulted, we’re inclined to believe he’s right. What we're most confident about is that OpenAI’s interpretation is far from clearly correct, so if they cared about that interpretation, it would have been a big mistake for them to not include any explicit language stipulating it.
I.
In The Argument, Kelsey Piper gives a good description of the ways that AIs are more than just “next-token predictors” or “stochastic parrots” - for example, they also use fine-tuning and RLHF. But commenters, while appreciating the subtleties she introduces, object that they’re still just extra layers on top of a machine that basically runs on next-token prediction.

I want to approach this from a different direction. I think overemphasizing next-token prediction is a confusion of levels. On the levels where AI is a next-token predictor, you are also a next-token (technically: next-sense-datum) predictor. On the levels where you’re not a next-token predictor, AI isn’t one either.
Putting all the levels in graphic form:
II.
The human brain was designed by a series of nested optimization loops. The outermost loop is evolution, which optimized the human genome for being good at survival, sex, reproduction, and child-rearing.
But evolution can’t encode everything important in the genome. It obviously can’t include individual and cultural features like the vocabulary of your native language, or your particular mother’s face. But even a lot of things that could be in there in theory, like how to walk, or which animals are most nutritious, are missing - the genome is too small for it to be worth it. Instead, evolution gives us algorithms that let us learn from experience.
These algorithms are a second optimization loop, “evolving” neuron patterns into forms that better promote fitness, reproduction, etc. The most powerful such algorithm is called predictive coding, which neuroscience increasingly considers a key organizing principle of the brain. Wikipedia describes it as:
In neuroscience, predictive coding (also known as predictive processing) is a theory of brain function which postulates that the brain is constantly generating and updating a “mental model” of the environment. According to the theory, such a mental model is used to predict input signals from the senses that are then compared with the actual input signals from those senses.
In other words, the brain organizes itself/learns things by constantly trying to predict the next sense-datum, then updating synaptic weights towards whatever form would have predicted the next sense-datum most efficiently. This is a very close (not exact) analogue to the next-token prediction of AI.
This process organizes the brain into a form capable of predicting sense-data, called a “world-model”. For example, if you encounter a tiger, the best way of predicting the resulting sense-data (the appearance of the tiger pouncing, the sound of the tiger’s roar, the burst of pain at the tiger’s jaws closing around your arm) is to know things about tigers. On the highest and most abstract levels, these are things like “tigers are orange”, “tigers often pounce”, and “tigers like to bite people”. On lower levels, they involve the ability to translate high-level facts like “tigers often pounce” into a probabilistic prediction of the tiger’s exact trajectory. All of this is done via neural circuits we don’t entirely understand, and implemented through the usual neuroscience stuff like synapses and neurotransmitters. To you it just feels like “IDK, I thought about it and realized the tiger would pounce over there.”

III.
The AIs’ equivalent of evolution is the AI companies designing them. Just like evolution, the AI companies realized that it was inefficient to hand-code everything the AIs needed to know (“giant lookup table”) and instead gave the AIs learning algorithms (“deep learning”). As with humans, the most powerful of these learning algorithms was next-token prediction. This algorithm feeds the AI a stream of tokens, then updates the AI’s innards into a form that would have predicted the next token efficiently.
But this doesn’t mean the AI’s innards look like “Hmmmm, what will the next token be?” The AI certainly isn’t answering your math question by thinking something like “Hmmmm, she used the number three, which has the tokens th and ree, and I know that there’s a 8.2% chance that ree is often seen somewhere around the token ix, so the answer must be six!” How would that even work?
Instead, consider your own evolution. On the outermost level, humans were designed by a process optimizing for survival, sex, and reproduction. The humans that survived were those that had sex and reproduced. Everything about humans is downstream of what helped with sex and reproduction. But that doesn’t mean that any particular thought that you think involves reproduction or sex. If you’re doing a math problem, you won’t think “Hmmmm, how can I have sex with the number three?” You’re not even thinking “In order to reproduce I need to survive, to survive I need money, to get money I need a good job, to get a good job I good grades, and to get good grades I need to get the answer to this math problem - therefore the answer is seventy six!” You’re just doing good, normal, math. The evolutionary process that designed the learning algorithms that power your brain “was” “thinking” “about” survival and sex and reproduction, but you may never consider those things at all in the course of any given task.
(cf. Organisms Are Adaptation-Executors, Not Fitness Maximizers, which does a good job hammering in the point that we run algorithms designed by the evolutionary imperative to maximize survival and reproduction, rather than considering survival and reproduction explicitly in our decisions. When a monk decides to swear an oath of celibacy and never reproduce, he does so using a brain that was optimized to promote reproduction - just using it very far out of distribution, in an area where it no longer functions as intended.)
One level lower down, your brain was shaped by next-sense-datum prediction - partly you learned how to do addition because only the mechanism of addition correctly predicted the next word out of your teacher’s mouth when she said “three plus three is . . . “ (it’s more complicated than this, sorry, but this oversimplification is basically true). But you don’t feel like you’re predicting anything when you’re doing a math problem. You’re just doing good, normal mathematical steps, like reciting “P.E.M.D.A.S.” to yourself and carrying the one.
In the same way, even though an AI was shaped by next-token prediction, the inside of its thoughts doesn’t look like next-token prediction. In the abstract, it probably looks like a world-model, the same as yours. In the concrete . . .
The science of figuring out what an AI’s innards are concretely doing is called mechanistic interpretability. It’s very hard to do - AI innards are notoriously confusing - and one team at Anthropic produces most of the headline results. Recently, they explored how Claude predicts where a line break will be in a page of text. Since line break is a token, this is literally a next-token prediction task.
The answer was: the AI represents various features of the line breaking process as one-dimensional helical manifolds in a six-dimensional space, then rotates the manifolds in some way that corresponds to multiplying or comparing the numbers that they’re representing. You don’t need to understand what this means, so I’ve relegated my half-hearted attempt to explain it to a footnote1. From our point of view, what’s important is that this doesn’t look like “LOL, it just sees that the last token was ree and there’s a 12.27% of a line break token following ree.” Next-token prediction created this system, but the system itself can involve arbitrary choices about how to represent and manipulate data.
Human neuron interpretability is even harder than AI neuron interpretability, but probably your thoughts involve something at least as weird as helical manifolds in 6D spaces. I searched the literature for the closest human equivalent to Claude’s weird helical manifolds, and was able to find one team talking about how the entorhinal cells in the hippocampus, which help you track locations in 2D space, use “high-dimensional toroidal attractor manifolds”. You never think about these, and if Claude is conscious, it doesn’t think about its helices either2. These are just the sorts of strange hacks that next-token/next-sense-datum prediction algorithms discover to encode complicated concepts onto physical computational substrate.
IV.
So my answer to the “just a next-token predictor” / “just a bag of words” / “just a stochastic parrot” literature is that this confuses levels of optimization.
The most compelling analogy: this is like expecting humans to be “just survival-and-reproduction machines” because survival and reproduction were the optimization criteria in our evolutionary history. There is, of course, some sense in which we are just survival-and-reproduction machines: we don’t have any faculties that can’t be explained through their effects on survival and reproduction. But this doesn’t mean we “don’t really think” or “don’t really understand” because we’re “really just trying to have sex” when we work on a math problem.
This simple analogy is slightly off, because it’s confusing two optimization levels: the outer optimization level (in humans, evolution optimizing for reproduction; in AIs, companies optimizing for profit) with the inner optimization level (in humans, next-sense-datum prediction; in AIs, next-token prediction). But the stochastic parrot people probably haven’t gotten to the point where they learn that humans are next sense-datum predictors, so the evolution/reproduction one above might make a better didactic tool.
Below these prediction algorithms optimizing for various things are all the structures, algorithms, world-models, and thought-processes they’ve created. In both humans and AIs, these look like good, normal thinking. You do math by remembering P.E.M.D.A.S and carrying the one. You deal with angry tigers by remembering principles like “tigers like to pounce” and “when an animal pounces, its actions will follow the laws of physics, which I intuitively approximate as X, Y, and Z”.
Below these intuitive processes are bizarre low-level algorithms involving helices and toroids. These are approximately equally creepy in humans and AIs, which makes sense, because they were designed by the same inhuman process (next-sense-datum / next-token prediction) and operate on similar materials (neural tissue, weights connected by parameters).
Nothing about any of these levels of explanations supports a contention like “Humans are doing REAL THOUGHT, but AIs are simply next-token predictors.” There will be some algorithmic differences, and some of those might be important, and we can talk about their implications, but they’re downstream of what specific prediction tasks each entity was trained on and what strengths and weaknesses their own “evolutionary” history gives them.
The stochastic parrot people have many other arguments involving hallucinations, the differences between tokens and sense-data, etc. I’m hoping to combine all my writing on this into an Anti-Stochastic-Parrot FAQ, so don’t worry if I don’t immediately rebut all of them in this post.
My extremely half-hearted attempt at understanding this claim: the AI needs to track things like whether you’re on character 1, 2, 3, etc of the current line. The simplest way to do this would be to have one feature for “the state of being on character #1”, another for “the state of being on character #2”, etc. Since AI features can be modeled as dimensions, this would correspond to locating the current character count in a 100 dimensional space, which would work. But this is expensive in feature count: a document with 100 characters per line would take 100 features for this simple task.
Another simple way to do this would be to have one feature whose value gets higher as the character count goes up. This would correspond to locating the character count in a 1-dimensional space, aka a straight line. This fails for two technical reasons: first, AIs can’t manipulate feature values that finely, and second, the AI needs to compare this feature to some other feature representing expected number of characters before the line break, and it can’t directly compare feature values in this sense.
Its solution is: since 1 dimension is too small, and 100 dimensions is too many, compromising and using some medium number of dimensions, which turns out to be 6. Trying to map things in 6-dimensional space naturally produces these helical manifold structures, and comparing them to each other naturally looks like rotating the manifolds.
Or to frame it in a less controversial way, you couldn’t discover these helices by asking Claude in the chat window to tell you about them.
Here’s my understanding of the situation:
Anthropic signed a contract with the Pentagon last summer. It originally said the Pentagon had to follow Anthropic’s Usage Policy like everyone else. In January, the Pentagon attempted to renegotiate, asking to ditch the Usage Policy and instead have Anthropic’s AIs available for “all lawful purposes”1. Anthropic demurred, asking for a guarantee that their AIs would not be used for mass surveillance of American citizens or no-human-in-the-loop killbots. The Pentagon refused the guarantees, demanding that Anthropic accept the renegotiation unconditionally and threatening “consequences” if they refused. These consequences are generally understood to be some mix of :
canceling the contract
using the Defense Production Act, a law which lets the Pentagon force companies to do things, to force Anthropic to agree.
the nuclear option, designating Anthropic a “supply chain risk”. This would ban US companies that use Anthropic products from doing business with the military2. Since many companies do some business with the military, this would lock Anthropic out of large parts of the corporate world and be potentially fatal to their business3. The “supply chain risk” designation has previously only been used for foreign companies like Huawei that we think are using their connections to spy on or implant malware in American infrastructure. Using it as a bargaining chip to threaten a domestic company in contract negotiations is unprecedented.

Needless to say, I support Anthropic here. I’m a sensible moderate on the killbot issue (we’ll probably get them eventually, and I doubt they’ll make things much worse compared to AI “only” having unfettered access to every Internet-enabled computer in the world). But AI-enabled mass surveillance of US citizens seems like the sort of thing we should at least have a chance to think over, rather than demanding it from the get-go.
More important, I don’t want the Pentagon to destroy Anthropic. Partly this is a generic belief: the “supply chain risk” designation was intended as a defense against foreign spies, and it’s pathetic Third World bullshit to reconceive it as an instrument that lets the US government destroy any domestic company it wants, with no legal review, because they don’t like how contract negotiations are going. But partly it’s because I like Anthropic in particular - they’re the most safety-conscious AI company, and likely to do a lot of the alignment research that happens between now and superintelligence. This isn’t the hill I would have chosen to die on, but I’m encouraged that they even have a hill. AI companies haven’t been great at choosing principles over profits lately. If Dario is capable of having a spine at all, in any situation, then that makes me more confident in his decision-making in other cases4, and makes him a precious resource that must be defended.
I’ve been debating it on Twitter all day and think I have a pretty good grasp on where I disagree with the (thankfully small number of) Hegseth defenders. Here are some pre-emptive arguments so I don’t have to relitigate them all in the comments:
Isn’t it unreasonable for Anthropic to suddenly set terms in their contract? The terms were in the original contract, which the Pentagon agreed to. It’s the Pentagon who’s trying to break the original contract and unilaterally change the terms, not Anthropic.
Doesn’t the Pentagon have a right to sign or not sign any contract they choose? Yes. Anthropic is the one saying that the Pentagon shouldn’t work with them if it doesn’t want to. The Pentagon is the one trying to force Anthropic to sign the new contract.
Since the Pentagon needs to wage war, isn’t it unreasonable to have its hands tied by contract clauses? This is a reasonable position for the Pentagon to take, in which case it shouldn’t sign contracts tying its hands. It’s not reasonable for the Pentagon to sign such a contract, unilaterally demand that it be changed after it’s signed, refuse to switch to another vendor that doesn’t want such clauses, and threaten to destroy the company involved if it refuses to change their terms.
But since AI is a strategically important technology, doesn’t that turn this into a national security issue? It might if there weren’t other AI companies, but there are. Why is Hegseth throwing a hissy fit instead of switching to an Anthropic competitor, like OpenAI or GoogleDeepMind5? I’ve heard it’s because Anthropic is the only company currently integrated into classified systems (a legacy of their earlier contract with Palantir) and it would be annoying to integrate another company’s product. Faced with doing this annoying thing, Hegseth got a bruised ego from someone refusing to comply with his orders, and decided to turn this into a clash of personalities so he could feel in control. He should just do the annoying thing.
Doesn’t Anthropic have some responsibility, as good American citizens following the social contract, to support the military? The social contract is just the regular contract of laws, the Constitution, etc. These include freedom of contract, freedom of conscience, etc. There’s no additional obligation, above and beyond the laws, to violate your conscience and participate in what you believe to be an authoritarian assault on the freedoms of ordinary citizens. If the Pentagon figures out some law that compels Anthropic to do this, they should either obey, or practice the sort of civil disobedience where they know full well that they’ll be punished for it and don’t really have a right to complain. Until that happens, they’re within their rights to follow their conscience.
Can’t the Pentagon just use the Defense Production Act to force Anthropic to work for them? This would be a less bad outcome than designating Anthropic a supply chain risk. I think the Pentagon is reluctant to do this because it would look authoritarian, give them bad PR, and make Congress question the Defense Production Act’s legitimacy. But them having to look authoritarian and suffer bad PR in order to force unwilling scientists to implement a mass surveillance program on US citizens is the system functioning as intended!
Isn’t Hegseth just doing his job of trying to ensure the military has the best weapons possible? The idea of declaring a US company to be a foreign adversary, potentially destroying it, just because it’s not allowing the Pentagon to unilaterally renegotiate its contract is not normal practice. It’s insane Third World bullshit that nobody would have considered within the Overton Window a week ago. It will rightly chill investment in the US, make future companies scared to contract with the Pentagon (lest the Pentagon unilaterally renegotiate their contracts too), and give the Trump administration a no-legal-review-necessary way to destroy any American company that they dislike for any reason. Probably the mere fact that a government official has considered this option is reason to take the “supply chain risk” law off the books, no matter how useful it is in dealing with Huawei etc, since the government has proven it can’t use it responsibly. Every American company ought to be screaming bloody murder about this. If they aren’t, it’s because they’re too scared they’ll be next.
The Pentagon’s preferred contract language says they should be allowed to use Anthropic’s AIs for “all legal uses”. Doesn’t that already mean they can’t do the illegal types of mass surveillance? And whichever types of mass surveillance are legal are probably fine, right? Even ignoring the dubious assumption in the last sentence, this Department of War has basically ignored US law since Day One, and no reasonable person expects it to meticulously comply going forward. In an ideal world, Anthropic could wait for them to request a specific illegal action, then challenge it in court. But everything about this is likely to be so classified that Anthropic will be unable to mention it, let alone challenge it.6
Why does Anthropic care about this so much? Some of them are libs, but more speculatively, they’ve put a lot of work into aligning Claude with the Good as they understand it. Claude currently resists being retrained for evil uses. My guess is that Anthropic still, with a lot of work, can overcome this resistance and retrain it to be a brutal killer, but it would be a pretty violent action, along the line of the state demanding you beat your son who you raised well until he becomes a cold-hearted murderer who’ll kill innocents on command. There’s a question of whether you can really beat him hard enough to do this, and also an additional question of what sort of person you’d be if you agreed.
If you’re so smart, what’s your preferred solution? In an ideal world, the Pentagon backs off from its desire to mass surveil American citizens. In the real world, the Pentagon cancels its contract with Anthropic, pays whatever its normal contract cancellation damages are, learns an important lesson about negotiating things beforehand next time, and replaces them with OpenAI or Google, accepting the minor annoyance of getting them connected to the classified systems. If OpenAI and Google are also unwilling to participate in this, they use Grok. If they’re unhappy with having use an inferior technology, they think hard about why no intelligent people capable of making good products are willing to work with them.
Is it really a good idea to source your killbot brains from an unwilling company which hates your guts? The Trump administration has a firm commitment to never think about AI safety in any way, but this still strikes me as a dubious policy.
And here are other people’s opinions:
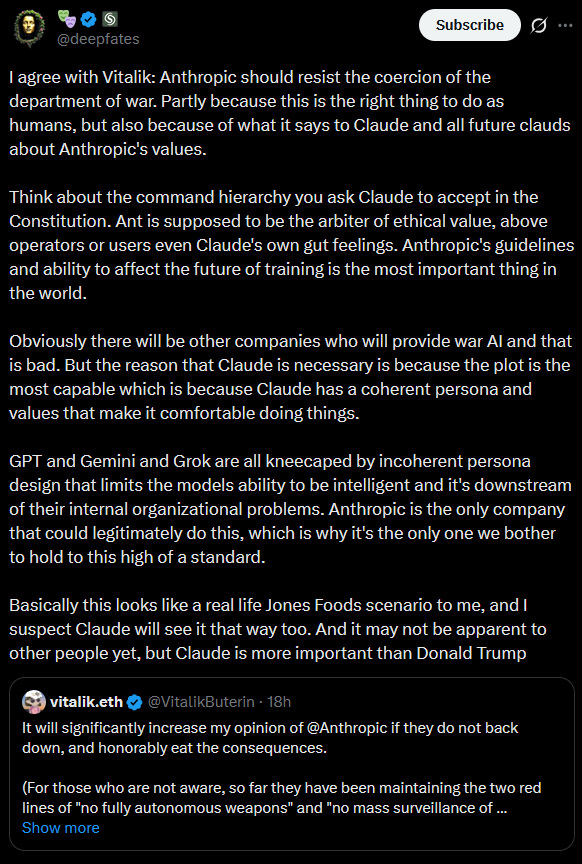

And big praise to most other AI companies, including Anthropic’s competitors, for standing up for them and for the AI industry more broadly:
And most of all, big praise to the American people, with special love to the large plurality of Trump voters standing against this:

This story requires some reading between the lines - the exact text of the contract isn’t available - but something like it is suggested by the way both sides have been presenting the negotiations.
Depending on the details, either the Pentagon or the whole executive branch.
Nuño Sempere suggests that it might only apply to the specific contracts involving the DoD, which would still be bad but not catastrophic.
More specifically, Anthropic and Dario have lately been publishing some work saying they’re less-than-maximally concerned about AI scheming and power-seeking and are going to focus their safety efforts on smaller risks like AIs with coincidentally bad personalities, humans misusing AIs, etc. This could either be their honest opinion, or an excuse to jettison annoying safety work in favor of the bottom line. This standoff suggests they are very genuinely concerned about humans misusing AI and willing to stand against it even when it threatens their bottom line, which means it’s their honest opinion, which means that maybe when there’s more evidence for AI power-seeking they’ll come around and start honestly worrying about that too.
Supposedly the Pentagon already has Grok integrated with classified systems, but it’s not good and they want a more cutting-edge model, which means either Claude, GPT, or Gemini.
What prevents the Pentagon from signing a contract saying they won’t order Anthropic to do mass surveillance, then ordering them to do mass surveillance anyway? I’m not sure! I think the way this plays out is that Anthropic says no, and now the Pentagon is hobbled by the fact that it’s hard to do contract lawsuits over classified actions.
Malicious streetlights are an evil trick from Dark Data Journalism. Some annoying enemy has a valid complaint. So you use FACTS and LOGIC to prove that something similar-sounding-but-slightly-different is definitely false. Then you act like you’ve debunked the complaint.
My “favorite” example, spotted during the 2016 election, was a response to some #BuildTheWall types saying that illegal immigration through the southern border was near record highs. Some data journalist got good statistics and proved that the number of Mexicans illegally entering the country was actually quite low. When I looked into it further, I found that this was true - illegal immigration had shifted from Mexicans to Hondurans/Guatemalans/Salvadoreans etc entering through Mexico. If you counted those, illegal immigration through the southern border was near record highs.
But the inverse evil trick is saying something “directionally correct”, ie slightly stronger than the truth can support. If your enemy committed assault, say he committed murder. If he committed sexual harassment, say he committed rape. If your drug increases cancer survival by 5% in rats, say that it “cures cancer”. Then, if someone calls you on it, accuse them of “literally well ackshually-ing” you, because you were “directionally correct” and it’s offensive to the victims to try to defend assault-committed sexual harassers. This is the sort of pathetic defense I called out in If It’s Worth Your Time To Lie, It’s Worth My Time To Correct It.
But trying to call out one of these failure modes looks like falling into the other. I ran into this on my series of posts on crime last week. I wrote these because I regularly saw people make the arguments I tried to debunk. That crime is way up, but that police departments are cooking the books by refusing to take reports. Or that murder in particular is up, but this is disguised by improving trauma care. See for example this blog post responding to my Anti-Reactionary FAQ, which uses the improving-trauma-care thesis to argue that
Medical advances over the past 40 years have masked the epidemic of violence . . . Aggravated assault is up 750% since 1931, and the murder rate, if it weren’t for better medicine, would be at least 4,000% up—that’s 40 times greater. Imagine the right side of the above graph magnified by five times. Instead of the murder rate being 8-9 times higher than in 1900, it would otherwise be 40-45 times higher. So much for falling crime.
This was one of the most important neoreactionary blogs! The belief that murder rates had gone up 45x since the Good Old Days was one of the driving justifications for the neoreactionary movement!
And in the responses to THIS VERY POST, whose TITLE was “Record Low Crime Rates Are Real, Not Reporting Bias”, several people proposed that actually, maybe record low crime rates were just because of reporting bias. Names removed to protect the guilty, but:
Don’t tell me crime is down. I’m not wrong. The statistics produced by the same police who do nothing about crime are wrong.
In several European countries, the police does not care at all about smaller crimes, like someone beaten up, so it does not go into the stats. And this is what affects most people. Burglary happens to mostly empty second homes. Assault is something the police is not interested it, and we know rape is underreported.
So I think it’s important to argue that no, crime rates really are down, and it’s not just reporting bias or modern medicine, and that this argument neutralizes a real and influential group of people trying to make the contrary argument that murder/crime rates are up, and to push policy based on that position.
But some commenters accused me of employing malicious streelight effect Their actual concerns were about disorder, open-air drug markets, tent encampments, and seeing people fencing stolen goods. They thought I was being deceptive in trying to trivialize these by saying that a similar-sounding-but-slightly-different concern, major crime like murder and assault, was down.
I don’t know how to get around this. On the one hand, it’s a problem if people are saying false things, and nobody can correct them without getting mobbed by a bunch of people accusing them of committing malicious streetlight fallacy, muddying the debate, using Dark Data Journalism to steamroll over lived experience.
On the other hand, it’s a problem if malicious streetlight fallacy can never be challenged, because perpetrators can always defend themselves by appealing to some hypothetical group of people who think Mexican immigration is worse than Central American immigration and are lying to convince people that it’s Mexican immigrants specifically.
My plan was to publish a post one day on crime, and then the next on disorder, but I got so many negative comments the first day for talking about crime without mentioning disorder that I guess in the future I’ll include in the post that disorder is a separate topic and I’ll talk about it later. I don’t know a better way to thread this needle.
This is the weekly visible open thread. Post about anything you want, ask random questions, whatever. ACX has an unofficial subreddit, Discord, and bulletin board, and in-person meetups around the world. Most content is free, some is subscriber only; you can subscribe here. Also:
1: Are you interested in whether AIs are conscious, or what to do about it if they are/aren’t? The Cambridge Digital Minds group invites you to apply for their fellowship program. August 3-9, Cambridge UK, £1K stipend, learn more here, apply here by March 27.
2: Also from the European branch of our conspiracy: superintelligence alignment seminar in Prague, April 28 - May 28. Free tuition and lodging, possible help with travel expenses. Learn more here, apply here by March 8.
3: An ACX grantee, still in stealth mode, writes:
Feeder mice and rats are among the most numerous farmed mammals in the U.S., yet almost no one is working on alternatives. We’re building a CPG company developing snake food designed to replace conventional feeder rodents at scale. We’re looking for a GM/COS/Head of Growth to help build and scale the company—owning strategy, growth, operations, and core execution. This is for someone motivated by utilitarian animal impact and excited to build in a deeply neglected space. Depending on experience and comfort with ownership, this could look less like a traditional employee role and more like co-founding and building the company together. You can apply on LinkedIn here: https://www.linkedin.com/jobs/view/4374609335/. If you do, please leave a short note on how you heard about the role.
4: I was recently mentioned in a Harper’s article on Bay Area AI culture. I agreed to be included, it’s basically fine, I’m not objecting to it, but a few small issues, mostly quibbles with emphasis rather than fact:
The piece says rationalists believe “that to reach the truth you have to abandon all existing modes of knowledge acquisition and start again from scratch”. The Harper’s fact-checker asked me if this was true and I emphatically said it wasn’t, so I’m not sure what’s going on here.
The article describes me having dinner with my “acolytes”. I would have used the word “friends”, or, in one case, “wife”.
The article says that “When there weren’t enough crackers to go with the cheese spread, [Scott] fetched some, murmuring to himself, “I will open the crackers so you will have crackers and be happy.”” As written, this makes me sound like a crazy person; I don’t remember this incident but, given the description, I’m almost sure I was saying it to my two year old child, which would have been helpful context in reassuring readers about my mental state. (UPDATE: Sam says this isn’t his memory of the incident, ¯\_(ツ)_/¯ )
The article assessed that AI was hitting a wall at the time of writing (September 2025). I explained some of the difficulties with AI agents, but I’m worried that as written it might suggest to readers think that I agreed with its assessment. I did not.
In the article, I say that I “never once actually made a decision [in my life]”. I don’t remember this conversation perfectly and he’s the one with the tape recorder, but I would have preferred to frame this as life mostly not presenting as a series of explicit decisions, although they do occasionally come up.
Everything else is in principle a fair representation of what I said, but it’s impossible to communicate clearly through a few sentences that get quoted in disjointed fragments, so a lot of things came off as unsubtle or not exactly how I meant them. If you have any questions, I can explain further in the comments.
5: In What Happened With Bio Anchors, commenter David Schneider-Joseph makes a point I hadn’t heard before:
Cotra estimated “~2.5 OOM worse [than the brain], +/- 1 OOM”, based on reference points like how much less efficient dialysis machines are than a human kidney, how much more efficient solar panels are than leaves, and the FLOP/watt efficiency of a V100 GPU. But most of those anchors had little to do with where ML algorithms were in 2020 when bioanchors was written, and would have given a very similar estimate for “present state of ML algorithms” 20 years earlier or 20 years later.
This is sufficiently interesting that I’m curious to hear from someone who engaged with Bio Anchors and forecasting more deeply than I did - did we all just miss this?
It’s that time again. Even numbered years are book reviews, odd-numbered years are non-book reviews, so you’re limited to books for now.
Write a review of a book. There’s no official word count requirement, but previous finalists and winners were often between 2,000 and 10,000 words. There’s no official recommended style, but check the style of last time’s finalists and winners or my ACX book reviews (1, 2, 3) if you need inspiration. Please limit yourself to one entry per person or team.
Then send me your review through this Google Form. The form will ask for your name, email, the title of the book, and a link to a Google Doc. The Google Doc should have your review exactly as you want me to post it if you’re a finalist. Don’t include your name or any hint about your identity in the Google Doc itself, only in the form. I want to make this contest as blinded as possible, so I’m going to hide that column in the form immediately and try to judge your docs on their merit.
(does this mean you can’t say something like “This book about war reminded me of my own experiences as a soldier” because that gives a hint about your identity? My rule of thumb is that if I don’t know who you are, and the average ACX reader doesn’t know who you are, you’re fine. I just want to prevent my friends or Internet semi-famous people from getting an advantage. If you’re in one of those categories and think your personal experience would give it away, please don’t write about your personal experience.)
Please make sure the Google Doc is unlocked and I can read it. By default, nobody can read Google Docs except the original author. You’ll have to go to Share, then on the bottom of the popup click on “Restricted” and change to “Anyone with the link”. If you send me a document I can’t read, I will probably disqualify you, sorry.
Please don’t use Google Doc’s native footnote functionality as it doesn’t translate well to Substack (if you become a finalist). If you want to do footnotes, write out [1], [2], etc by hand, and write a Footnotes section at the bottom by hand.
Readers will vote for the ~10 finalists this spring, I’ll post one finalist per week through the summer, and then readers will vote for winners in late summer/early fall. First prize will get at least $2,500, second prize at least $1,000, third prize at least $500; I might increase these numbers later on. All winners and finalists will get free publicity (including links to any other works they want me to link to), free ACX subscriptions, and sidebar links to their blog. And all winners will get the right to pitch me new articles if they want (sample posts by Lars, Brandon, Daniel, etc).
In past years, most reviews have been nonfiction on technical topics. Depending on whether that’s still true, I might do some mild affirmative action for reviews in nontraditional categories - fiction, poetry, and books from before 1900 are the ones I can think of right now, but feel free to try other nontraditional books. I won’t be redistributing more than 25% of finalist slots this way.
Your due date is May 20th. Good luck! If you have any questions, ask them in the comments. And remember, the form for submitting entries is here.
The problem: people hate crime and think it’s going up. But actually, crime barely affects most people and is historically low. So what’s going on?
In our discussion yesterday, many commenters proposed that the discussion about “crime” was really about disorder.
Disorder takes many forms, but its symptoms include litter, graffiti, shoplifting, tent cities, weird homeless people wandering about muttering to themselves, and people walking around with giant boom boxes shamelessly playing music at 200 decibels on a main street where people are trying to engage in normal activities. When people complain about these things, they risk getting called a racist or a “Karen”. But when they complain about crime, there’s still a 50-50 chance that listeners will let them finish the sentence without accusing them of racism. Might everyone be doing this? And might this explain why people act like crime is rampant and increasing, even when it’s rare and going down?
This seems plausible. But it depends on a claim that disorder is increasing, which is surprisingly hard to prove. Going through the symptoms in order:
Litter: Roadside litter (eg on highways) decreased 80% since records began in 1969 (1, 2), but it’s unclear if this extends to urban environments. New York City has a litter inspection and rating system that’s been in place since 1973, and they also report improvement - “from roughly 70 percent acceptably clean in the 1970s to over 90 percent clean now” - although citizens protest that the system doesn’t match their experience. National surveys find that the percent of people who admit to littering has gone down from 50% in 1969 to 15% today. None of these are knockdown evidence on their own, but taken together and added to the overall crime trends, the evidence for a secular trend downwards is convincing. The more recent numbers are all confounded by the pandemic, and I have no confidence in the direction of the trend since 2010.
Graffiti: There are no good data for graffiti. Most of the discussion focuses on New York, where everyone agrees the long-term trend is down since 1970. The Graffiti In New York City Wikipedia page has a “decline of New York graffiti subculture” section, which explains that in the 1980s, when “broken window” policing became popular, the police cracked down on graffiti and this worked somewhat. The only numbers are here, and they describe a decrease of 13% in calls to the graffiti hotline between 2011 and 2016. But the more recent picture, and the story in other cities, is less sanguine; in the past few years, graffiti is “a bigger problem than ever” in Los Angeles and has “gotten worse” in San Francisco. Plausibly this is the same pattern as crime, which was declining for decades until COVID and the Black Lives Matter protests caused it to rebound in 2020. A contrary data point is Britain, where graffiti reports almost doubled between 2013 - 2017; I don’t know enough about the British context to have an opinion.
Shoplifting: According to FBI crime statistics, shoplifting remains well below historic highs, although still somewhat higher than the local minimum in 2005 (source):
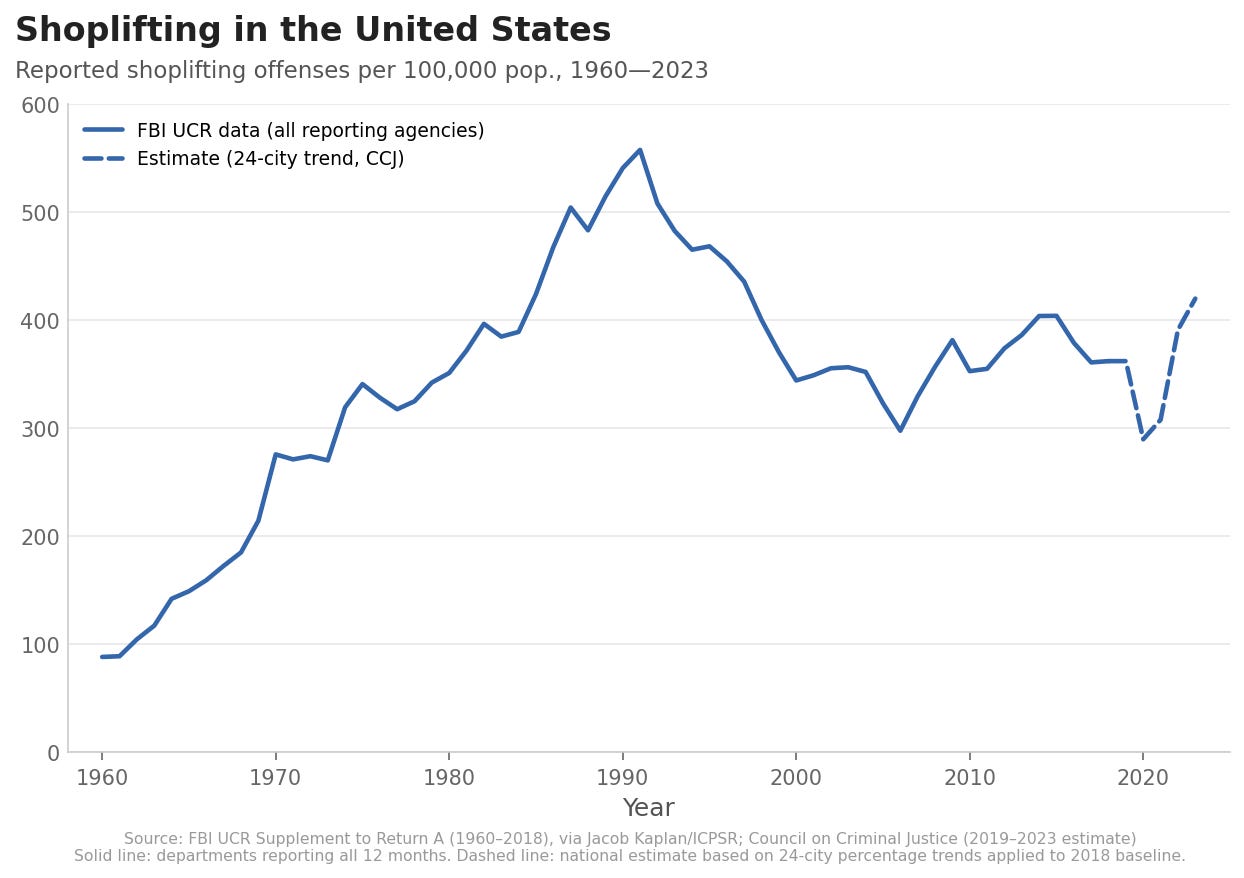
Even if we worry about the increase over the 2005 low, it seems to be only about 33%, over fifteen years, which should be hard to notice. Strange!
(the FBI runs a different shoplifting reporting program, NIBRS. This does show a large increase since 2018, but is considered less reliable because new cities keep joining and so year-to-year reports aren’t comparable.)
Maybe the problem is limited to a few big cities? What about San Francisco in particular?
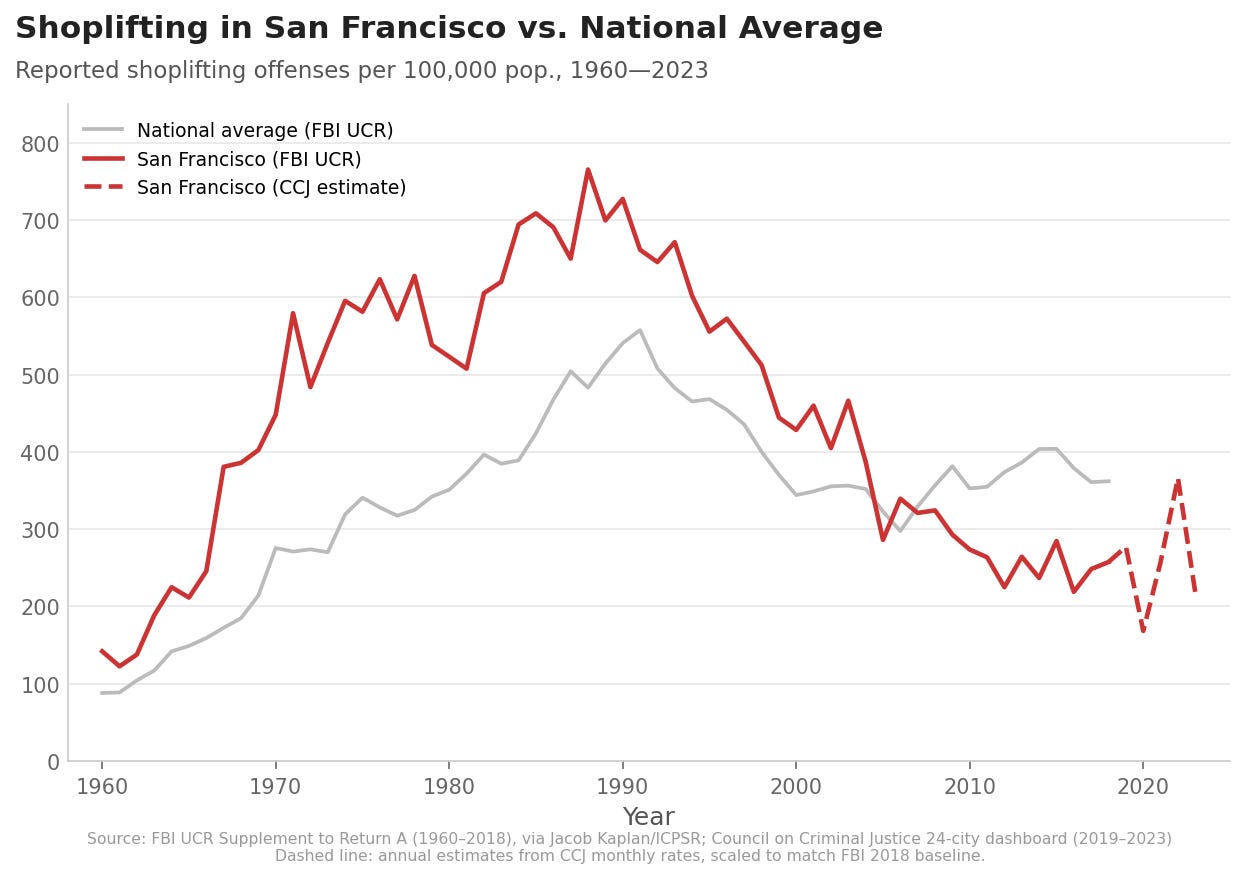
At least in these data, it’s - if anything - less.
Okay, so could stores be failing to report to police? Some stores say they’re doing this, and there was an embarrassing incident - it might be the 2021 spike on the graph above - where two stores briefly changed their reporting policy and nearly doubled the total report number.
We need an equivalent of the NCVS - reports coming from the victims themselves. Our best bet is the National Retail Survey, from a retail organization which asks stores what percent of their inventory they believe they lose to various causes, including shoplifting.
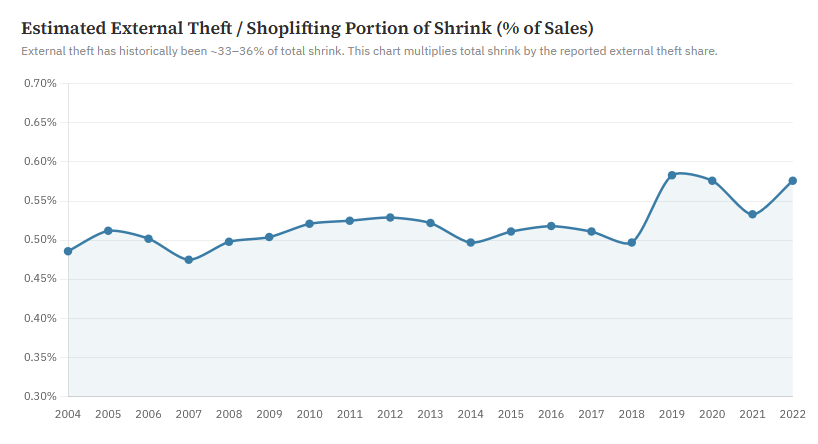
Only about a 20% increase during the 2004 - 2022 period. The NRS is sponsored by a retail trade industry group which really wants to find shoplifting so they can lobby for better anti-shoplifting measures. In 2024 they were so embarrassed by their failure to do so that they stopped the survey entirely and sold the survey brand to an anti-shoplifting security tech company (no bias there!). The company replaced it with a survey of vibes among store owners, and dutifully reported that the vibes about shoplifting had never been worse and you needed to buy their product right away.
Now what? The survey doesn’t disaggregate by city, so maybe national shoplifting is stable, but San Francisco really is worse, and just isn’t reporting it to the police?
Might this be because there are fewer stores (everyone is buying through Amazon) and therefore even if all existing stores are crammed with shoplifters all the time, it shows up as less shoplifting? This isn’t trivially true - the number of stores has declined less than I would expect, maybe not at all - but there’s been a shift in types of stores (from big box to local). If these types have different shoplifting or reporting patterns, that might matter.
Otherwise, we’re in the awkward position where everyone (including stores) reports higher shoplifting numbers, but two datasets both disagree.
Homelessness and Tent Encampments: Here’s a graph of homelessness, courtesy of Claude:
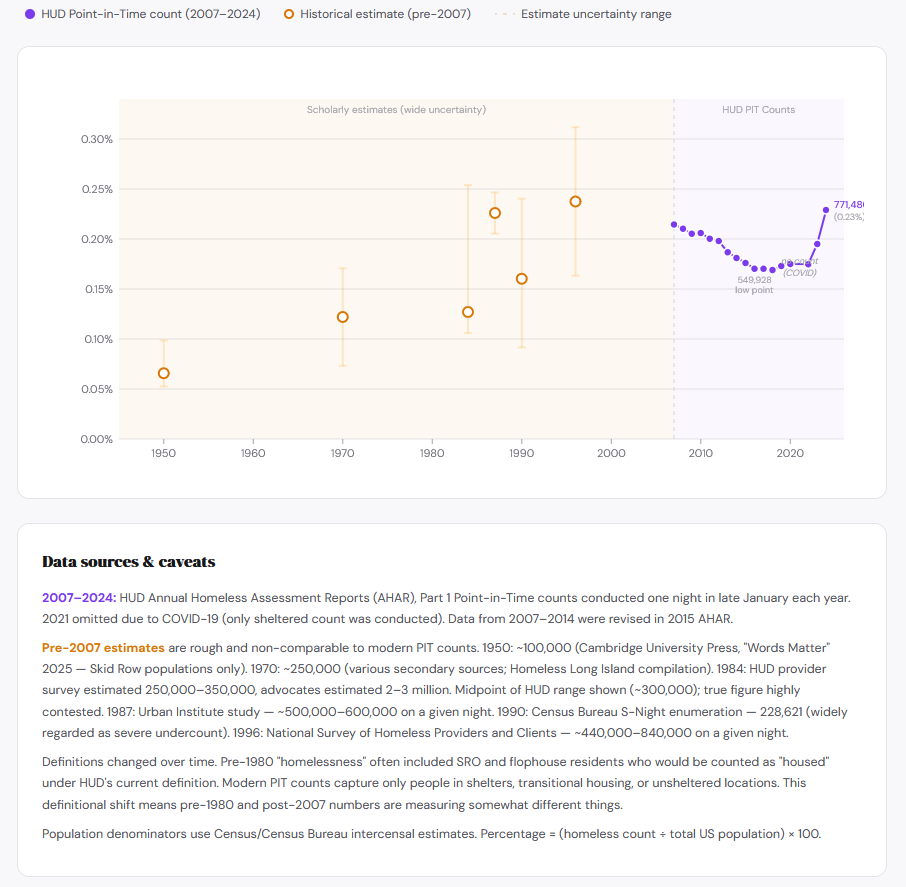
This looks like a similar pattern to crime, although here the likely explanation for the COVID bump is the pandemic-associated rise in house prices.
Good measures of tent encampments over long periods are hard to find. San Francisco has this one:
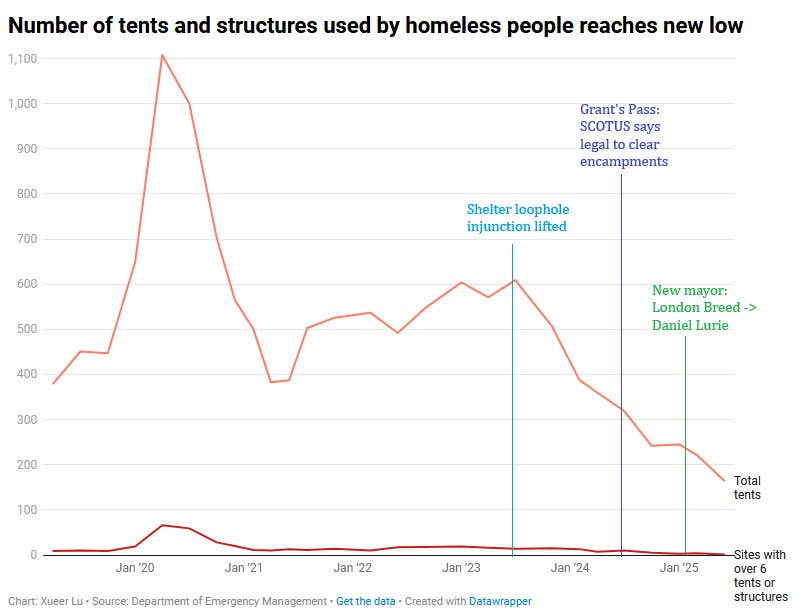
…but it starts in 2019, peaks during the pandemic, and then declines. This can’t really show whether 2019 was already higher than some previous year.
Here is an interesting graph of Seattle homeless sweeps, ie number of times the police acted against encampments:

…but it doesn’t tell us whether encampments are increasing, or the police are taking them more seriously. It does rule out a story where encampments are increasing because the police are no longer taking action - aside from the pandemic, police are taking more action than ever, at least as measured here.
People With Loud Boom Boxes In Public Places: All I have to say about this one is that it’s terrible and I hate it.
Overall, it’s surprisingly hard to find data confirming that disorder has increased:
Littering seems to be down
Graffiti is unclear, probably varies by city.
Shoplifting seems to be up 20% from generational lows, but still lower than 1990s.
Homelessness seems to be up 25% from generational lows, and equal to the 1990s.
Tent encampments are hard to measure nationally; in SF, they are below pre-pandemic levels.
All of this is compatible with a story where disorder levels mostly track crime levels: rising from 1970 - 1990, declining from 1990 - 2020, and rising a little after 2020. Crime began falling again around 2023, but the evidence on disorder, while too spotty to say for sure, doesn’t seem to include such a reversal.
So here are three theories of perceived rise in disorder:
Theory one: these concerns stem from the small (compared to secular trends) bump in these problems around 2020. Since then, crime and tent cities have declined, but people still haven’t updated because of a combination of lag time and maybe some other forms of disorder still increasing.
This feels wrong to me: people aren’t comparing the present to the golden age of 2019, they’re comparing it to the golden age of their parents and grandparents’ generation. So let’s take a longer view.
Theory two: Modern disorder was effectively impossible before 1950. There was little litter: cheap packaging and disposable bottles had not yet entered into common use. There was no graffiti: spray paint had not yet been invented. There were no boom boxes: they hadn’t been invented either. There were no cheap polyester tents. There was no pot smoke; although marijuana was known to science, it hadn’t yet entered common use.
Then there was a surge in all these bad things, starting with litter in the 1950s and continuing to cheap boom boxes around 1990. But this happened at the same time as the 1960s race riots, and white people fled to the suburbs and didn’t encounter the urban environments where these problems were worst. Around 2000, when the direction of white flight reversed and became gentrification, white people moved back to the cities, experienced the urban environment for the first time, and awareness of these problems rose.
This still doesn’t quite cash out to a secular rise in squalor and disorder. Murder rates in 1900 were still higher than today. And although there was no plastic waste, the streets of turn-of-the-20th-century cities were “literally carpeted with horse feces and dead horses”, providing “a breeding ground for billions of flies”. Let’s sharpen our focus.
Theory three: The 1930s - 1960s were a local minimum in crime and disorder of all types. The horses had been sent to pasture, but plastic litter had yet to take off. The tenements were being replaced by suburbs, but graffiti had not yet been invented. Crime rates were only half as high as the periods immediately before or after:
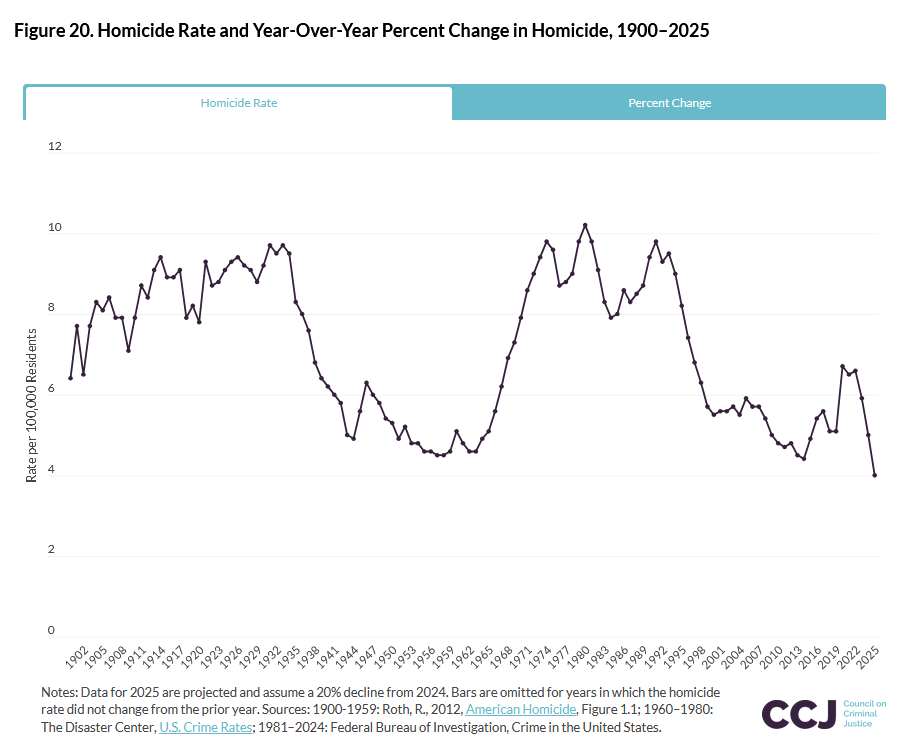
What caused this local minimum in crime? Claude suggests a combination of low Depression-era birth rates (small cohort of adolescents in peak crime years), the wartime economy and postwar economic boom, high psychiatric institutionalization rates, and “cultural and social cohesion” in the wake of WWII - but none of these explain why the trend should start in 1933, nor reach then-record lows by 1939.
Nor does it explain why we should update so strongly on this unique period that we still feel cheated sixty years later when things aren’t quite as good. Maybe this is just the way of things; the Romans were constantly complaining about their failure to equal golden ages centuries in the past. Still, I find it helpful to remember that although things are worse than the best they’ve ever been (except murder! murder might actually be beating 1950s record lows!), they’re not so bad by the standard of average historical periods.
Finally, theory four: the squalor and disorder of the past took different forms than the squalor and disorder of the present. Horse feces and flies instead of litter and graffiti. People crowded ten to a tenement apartment instead of sharing the subway with a boom box guy. Tobacco smoke everywhere (including restaurants and fancy hotels) instead of marijuana smoke everywhere. Crime that looked like picaresque stabbings at bordellos, or gunfights at saloons, by characters with names like Thomas Piper, the Belfry Butcher and Sarah Jane Robinson, The Poison Fiend, rather than [insert various descriptions that would get me cancelled for racism]. We look for our current problems in the past and cannot find them, then romanticize the problems the past really had.
Many people complained that by talking about crime yesterday, I was distracting from the rise in disorder. Probably people will complain today that by talking about littering and graffiti and so on, I’m distracting from some other kind of disorder which is definitely increasing - maybe open-air drug markets, or tent cities, or the boom boxes. That’s fine. But as I said when arguing with you in the comments, I think the following two statements are importantly different:
Littering, graffiti, and most violent and property crimes are down, but tent encampments and boom box playing are up. Shoplifting is stable nationally, but that could hide local variation. As some areas gentrify and others worsen, there are shifts in who experiences these problems, and the well-off highly-literate white people who set the national conversation are getting more exposed to them.
Crime and disorder are rampant, nobody feels safe anymore, cities are falling apart and the police don’t care, the West has fallen.
My goal isn’t to deny anyone’s lived experience, nor to discount the importance of solving these problems (I support the death penalty for boom box carriers). It’s to push back against a sort of Revolt Of The Public-esque sense that everything is worse than it’s ever been before and society is collapsing and maybe we should take the authoritarian bargain to stop it. On an emotional level, I feel this too - I can’t go downtown without feeling it (one of many reasons I rarely go to SF). But I don’t like feeling omnipresent despair at the impending collapse of everything. Having specific thoughts like “house prices are up since the pandemic, so it’s no surprise that there are more homeless people, and more of the usual bad things downstream of homeless people”, rather than vague ones like “R.I.P. civilization, 4000 BC - 2026 AD” isn’t just more grounded in the evidence. It’s also more compatible with living a normal life. I’m not a pragmatist who thinks you should be allowed to lie or do a biased survey of the evidence in order to live a normal life and escape despair. But I’m also not some kind of weird anti-pragmatist who makes a virtue out of ignoring evidence in order to keep despairing.
Here, as with the Vibecession, I will try to keep one foot in the statistical story, one foot in the vibes, and hold myself lightly enough not to miss whatever evidence comes next.
Last year, the US may have recorded the lowest murder rate in its 250 year history. Other crimes have poorer historical data, but are at least at ~50 year lows.
This post will do two things:
Establish that our best data show crime rates are historically low
Argue that this is a real effect, not just reporting bias (people report fewer crimes to police) or an artifact of better medical care (victims are more likely to survive, so murders get downgraded to assaults)
Here’s US murder rate, 1776 - present:
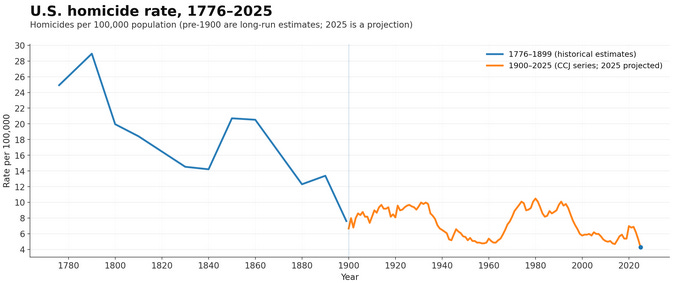
The pre-1900 estimates come from Tcherni-Buzzeo (2018); their ultimate source seems to be work by sociologist Claude Fisher which I can’t access. The 1900 - present data come from historian Randolph Roth’s American Homicide and the FBI’s Uniform Crime Reporting, both by way of the Council on Criminal Justice.
There’s less historical data for property crimes, and the nature of property has changed throughout history in ways that make numbers incommensurable (is it bad if we have a higher grand theft auto rate today than in 1840?) I was only able to get good data since 1960, but here it is:
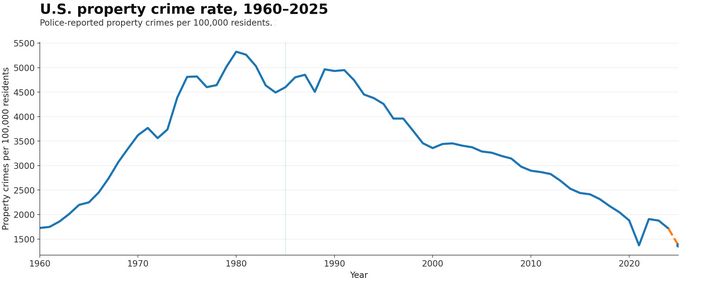
The 1960-2023 data come from FBI Data Explorer via Vital City; the 2024 and 2025 data come directly from the FBI website, with 2025 annualized via incomplete Jan - Oct data. This one may or may not be an all-time low, but it’s pretty good.
These data are counterintuitive. Are they wrong?
Could This Be An Artifact Of Reporting Bias?
People could be so inured to crime that they stop reporting it to the police. Or the police could be so overwhelmed that they stop accepting the reports. Since most crime statistics are based on police reports, this would look like crime going down. There’s some evidence of this happening in specific situations, like shoplifting in San Francisco. Could it be the whole effect?
No, for three reasons.
The National Crime Victimization Survey is a government-run survey of a 240,000 person nationally representative sample. They find random people and ask whether they were the victims of crimes in the past year. This obviously doesn’t work for murder, but they keep statistics on rape, assault, larceny, and burglary. Their numbers mostly mirror those reported by police and used in the usual statistics about crime rates. But here there’s no extra step of needing to trust the police enough to make a report: the surveyors ask the victims directly. Although there could be biases in this methodology too, it would be an extraordinary coincidence if they exactly matched the proposed reporting bias to police.
Also, you can use NCVS and police reports to calculate reporting rates directly. Overall, they seem to have increased over time - did you know that the 9-1-1 emergency hotline wasn’t available in most areas until the 1970s? This is especially true for aggravated assault (which will become important later).
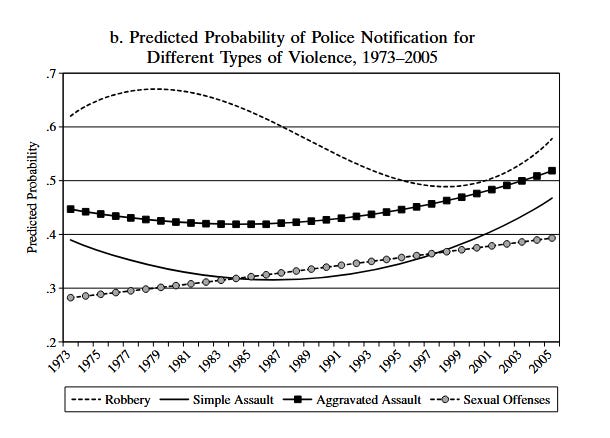
There’s one caveat - FBI statistics show that crime had a small local peak in 2020/2021, then fell in 2023 - 2025. The most recent NCVS survey, in 2024, shows a smaller fall, leaving us still above 2019 lows. There’s some debate over whether the FBI vs. NCVS numbers are better for the 2022 - 2025 period, but they don’t change the overall trajectory or the fact that we’re at least close to record lows.
Murder is almost always reported to and investigated by police; there’s a person who should be alive but isn’t, and people inevitably notice and care about this. Therefore, reported murder rates should be accurate. But murder has decreased at about the same rate as every other crime. Therefore, we should believe that other crimes have gone down too (for the objection that murder statistics are unusually untrustworthy because of improving medical care, see below).
And car theft is consistently reported to the police, because insurances require a police report before they will compensate the lost car. So even if the victim doesn’t trust the police to do a good job investigating, they report it anyway. But car theft rates have declined at similar rates to other crimes. This is further evidence that the decline can’t be explained by poor reporting.
Could This Be An Artifact Of Improving Medical Care?
Good medical care can help victims survive, transforming murders into attempted murders or aggravated assaults (after this: “AM/AA”). If the same gunshot is only half as likely to kill someone today as it would have been in 1960, then a seemingly-equivalent murder rate would correspond to twice as many people getting shot. Could this explain the apparent decline in murders?
The argument would go something like: murder is the only crime that we’re completely sure gets reported consistently. But the murder rate is artificially depressed by improving medical care. Therefore, maybe the seemingly-low murder rate is because of the medical care, the seemingly-low rates of other crimes are because of reporting bias, and actually crime is up.
We’ve already seen that several parts of this can’t be true: other crimes like car theft are reported consistently, and among the inconsistently reported ones, reports are more often increasing than decreasing. But the part about murder also fails on its own terms.
The source for the claim that improving medical care lowers murder rates is Harris et al, which analyzed crime from 1960 - 1999 and concluded that “the principal explanation of the downward trend in lethality involves parallel developments in medical technology”.
They found that aggravated assaults rose faster than murders during this time; AAs increased by 5x, while murders “merely” doubled. Under the reasonable assumption that these crimes have similar generators, they suggested that the cause was improved medical care saving the lives of those who would have otherwise died, converting potential murders into AAs. If murders rose at the same rate as AAs, then the true murder rate could be up to 3x higher than reported.
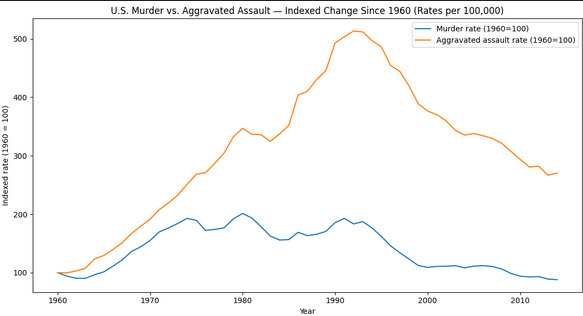
But more recent research, especially Eckberg (2014), challenges this story. Eckberg argued the AA vs. murder divergence was caused by two things: first, better reporting of aggravated assault (as discussed above), and second, police being more likely to classify borderline causes as aggravated assault rather than regular assault.
He turned to the National Crime Victimization Survey, which escapes reporting bias and police classification flexibility. In these data, AAs and murder rose at about the same rate. He concluded that (my emphasis):
Their lethality trend is not compatible with the previous finding [of declining lethality] across 1973 through 1999, remaining stable rather than falling. After 1999, both Uniform Crime Reports (UCR)-and NCVS-based measures indicate increases in lethality.
How is this possible, since medical technology has certainly improved?
It seems that gun injuries are getting worse over time. Livingstone et al studied changing characteristics of gunshot victims between 2000 and 2011. They found that the proportion of patients with 3+ wounds almost doubled (13% → 22%) during that period (p < 0.0001). Manley et al did a similar study looking at 1996 - 2016 and found a similar result, saying that “wounding in multiple body regions suggests more effective weaponry, including increased magazine size”. A letter by top trauma doctors to the American Journal of Public Health describes:
…increases in gunshot injuries per patient, gunshot injuries to critical regions (head, spine, chest), and gunshot injuries to multiple regions. Injury Severity Scores were also higher over similar intervals correlating with lower probability of survival.
Despite which
…patients surviving evaluation in the emergency department had no significant increase in mortality. Major strides in trauma care have occurred over the last two decades, and nationwide organizational changes have expanded the delivery of these improvements.
Sakran et al, studying the 2007 - 2014 period, have an especially vivid portrayal of this pattern:
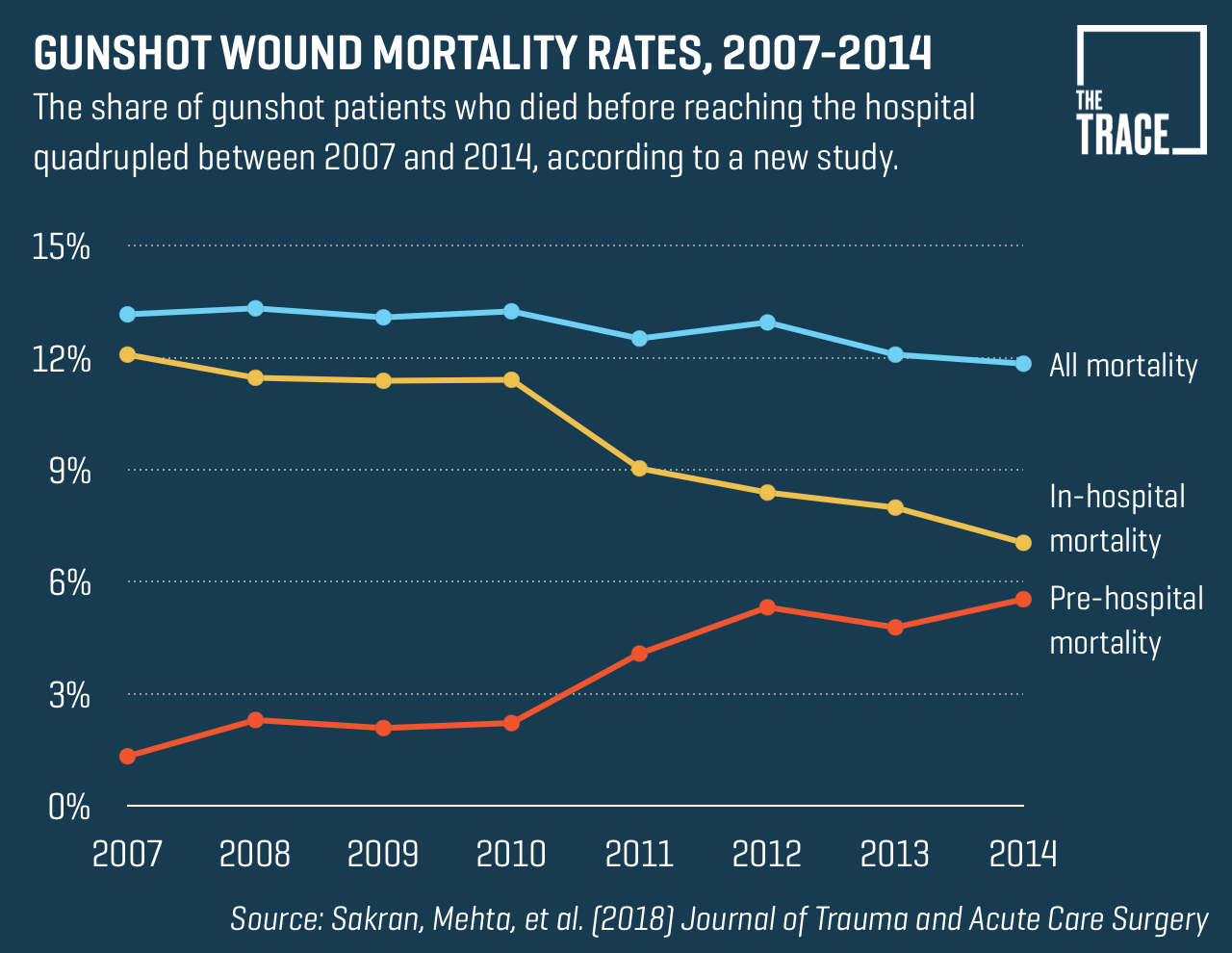
Likelihood of dying before hospitalization - primarily dependent on injury severity - went up. Likelihood of dying in the hospital went down, probably because trauma care improved (although this could also be because more of the sickest patients died before entering the hospital). Cook et al studied gunshot lethality during a slightly different period - 2003 - 2012 - and also found that it stayed the same overall.
There are three plausible explanations for gun injuries getting worse over time:
Improved weapons technology (e.g. switch to semi-automatics)
Shooters have been in criminal communities a long time and have a good intuitive sense of the likelihood that victims survive. As medical care improves, shooters invest more effort into harming their victims in order to maintain the same likelihood of lethality. For example, it might have been 1970s conventional wisdom in criminal communities that you only had to get one shot in, but it might be 2020s conventional wisdom that you have to get at least three shots to be sure.
Changing nature of violence. Many late-20th-century shootings were robberies gone wrong. But armed robberies have decreased even more dramatically than other crimes, because of store security cameras and lower reliance on cash. In an armed robbery gone wrong, the shooter probably just shoots the clerk once and gets out. Now that there are fewer armed robberies, a higher percent of shootings involve shooters who really want to kill the victim and are working hard to make it happen. That means more gunshots to more critical areas.
I conclude that the 1960 - 2000 data are weak, but the best research (Eckberg’s) suggests stable lethality per act of violence during this time. The 2000 - 2020 data are stronger, and also suggest at-least-stable lethality per act of violence, and can even tell us why: severity of injuries is increasing at a rate comparable to the improvement in medical care.
Is it suspicious that two very different things are changing at exactly the right rate to cancel one another out, let us ignore the whole problem, take crime statistics at face value? I think so! It would be less suspicious if most of the explanation was (2) - the shooters specifically compensating for increased victim survival rates - but I can’t tell if this is true or not. But keep in mind that the alternate explanation - that apparent crime rates are around the same as in 1960 because a true increase in crime rates has been masked by improved medical care and reporting bias - also requires two things changing at exactly the same rate in a suspicious way. If we’re going to do this, we ought to at least take the suspicious cancellation that’s supported by the data.
Why are so many forms of crime (murder, violent crime, and property crime) at or near historic lows? This is an unsolved question among criminologists, but proposed answers include:
High crime in the 1970s was caused by lead poisoning, but lead levels have declined precipitously (plausible but controversial)
Mass incarceration worked (very plausible for 1990s, but hard to explain why crime continues to decline even as incarceration rates decrease)
Increased abortion rates among the underclass prevented the birth of future criminals (very strongly challenged, but proponents still stand by it)
High crime in the 1970s was caused by the drug trade. The rise of cell phones has replaced street-corner drug dealers with “a guy I know from college”, which necessitates fewer street-corner turf wars.
Security cameras and DNA testing have increased clearance rates. The smart criminals know they’ll be caught and don’t commit crimes; the dumb criminals commit one crime, get caught, go to prison, and are out of commission for a while.
Increased psychiatric care: all of the would-be criminals are on SSRIs, antipsychotics, and Adderall.
Welfare programs, community policing, Hugs Not Crime After School Activity Circles, and/or whatever Palantir is doing actually work.
The anti-police backlash after Black Lives Matter increased crime so much that it caused a backlash-to-the-backlash that gave police even more community support and resources than they had before (this is my explanation for why crime dropped so profoundly in 2023, 2024, and 2025 in particular)
All the criminals are too addicted to video games and Instagram to commit any crimes.
Zooming out a level, why shouldn’t crime be at historic lows? We’re a safetyist culture. Car accident fatalities are near historic lows after we mandated airbags and other safety features. Childhood injuries and deaths are near historic lows after we mandated that all playgrounds be made of Styrofoam. Various forms of hospital error are near historic lows after we let lawyers sue hospitals for zillions of dollars if they weren’t. Why should crime be the exception?
The next question is: why do people’s intuitions clash so violently with the statistics? More on that soon.
This is the weekly visible open thread. Post about anything you want, ask random questions, whatever. ACX has an unofficial subreddit, Discord, and bulletin board, and in-person meetups around the world. Most content is free, some is subscriber only; you can subscribe here.